之前看大數學堂的教學影片學了爬蟲技巧還有 Spark,這回看到 David 老師要開課,當然要來參加講座呀,好在最後加開了三十個名額,讓我可以聽現場。這場 Workshop 主要介紹怎麼下載與使用 R studio,利用蘋果新聞網頁為例,練習怎麼爬取資料,並做簡單的分析。
老師的投影片與範例連結在此
https://github.com/ywchiu/rcrawler
總結今天教的軟體與工具
- R studio:免費開源軟體,跨平台的 R 語言 IDE
- Google chrome 開發者工具:Chrome 的內建工具,可以看原始碼,Layout 方式,連線資訊等等
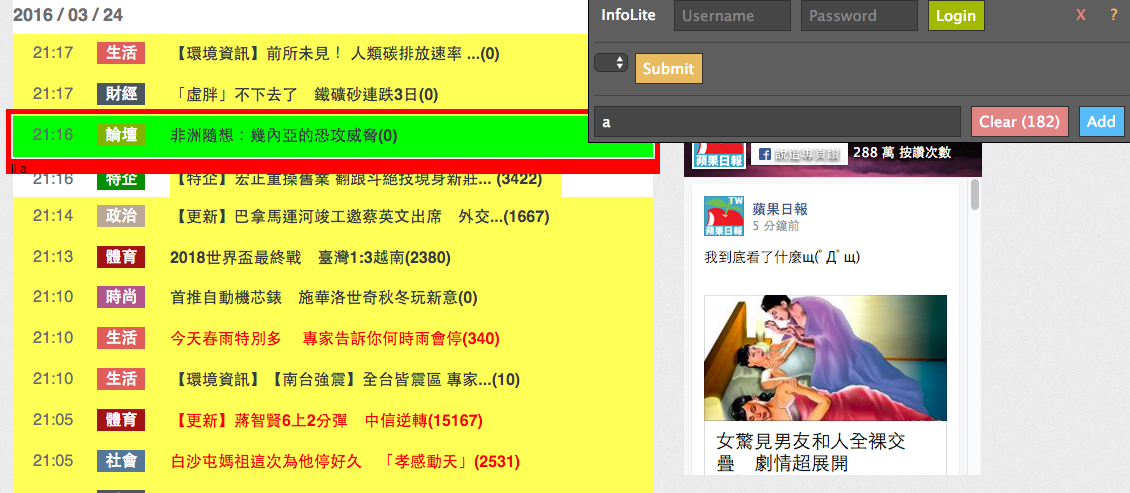
- Info Lite:老師所做的 Chrome 外掛,可以在瀏覽器上直接選擇所要的區塊並顯示標籤
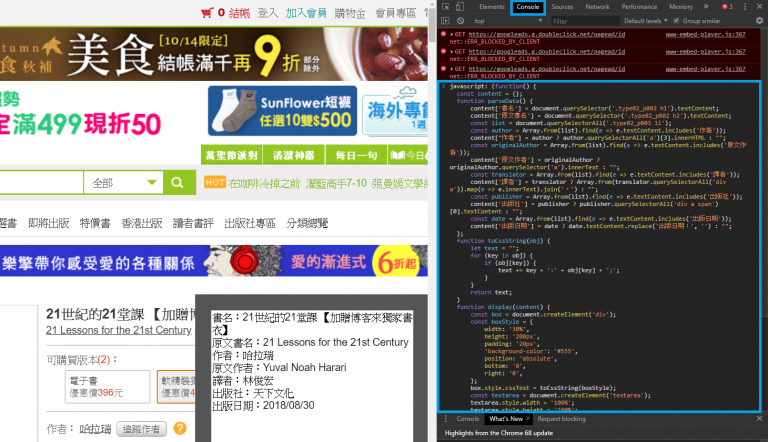
雖然 Google Chrome 開發者工具也可以選擇元素,但我覺得 Info lite 在選擇抓取元素時更為方便,他以顏色來做表示。選起來的區塊會變綠色,相同屬性區塊是黃色,不要的區塊是紅色,選完後右上方就可以看到最後選擇的標籤名稱。以下是實際的截圖:
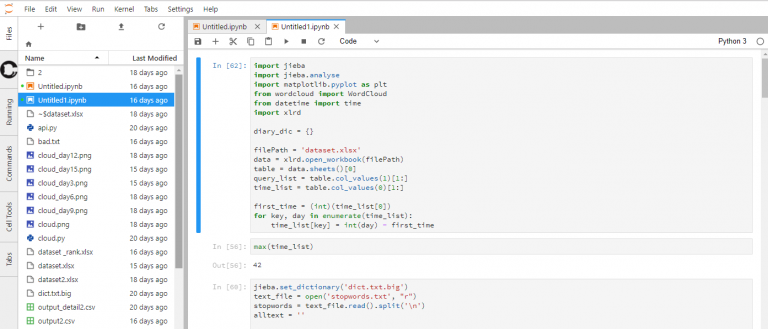
練習範例
需要載入 rvest 套件 以下抓取首頁新聞,分為 time, title, category, URL 儲存
library(rvest)
surl = "http://www.appledaily.com.tw/realtimenews/section/new/"
apple = read_html(surl,encoding="UTF-8")
apple %>% iconv(from = ‘UTF-8’, to = ‘UTF-8’)
rddt = apple %>% html_nodes(‘.rtddt’)
time = rddt %>% html_nodes(‘time’) %>% html_text()
title = rddt %>% html_nodes(‘h1’) %>% html_text() %>% iconv(from = ‘UTF-8’, to = ‘UTF-8’)
category = rddt %>% html_nodes(‘h2’) %>% html_text() %>% iconv(from = ‘UTF-8’, to = ‘UTF-8’)
domain = "http://www.appledaily.com.tw"
url = rddt %>% html_nodes(‘a’) %>% html_attr(‘href’)
url = paste0(domain, url)
news = data.frame(time=time, title=title, category=category, url=url)
抓取Facebook留言
很多網頁下方都會外掛 Facebook 的留言功能,但是他不好撈取,而且過度存取有可能會被 BAN 掉,所以應善用 Facebook Graph API來抓資料,並用 Graph API Explorer 來輔助學習。 Graph API Explorer 這部份由於時間關係沒有細講,之後有空再來研究