最近收到任務,希望在 Hadoop Cluster上面跑 Apache log 的分析案例,雖然之前已經架設過環境,但是純手工真的不是件容易事,遇到版本衝突、網路沒設好之類的問題會讓人一個頭兩個大。認真覺得裝(懂)過一次,了解 Hadoop 的安裝方式就可以了,為了快速完成目標,就直接用現成的雲端服務,開一個 Hadoop Cluster。 原本想用 Kubernetes (k8s) 架設,但是最近的 v1.6 版出問題 (Issue #43815),轉而使用 Google Container Engine (k8s v1.5),後來才發現 Google 其實有推出 Cloud Dataproc 服務,能直接幫架設好 Hadoop、Spark 環境,幾分鐘的時間就能建置完成!
什麼是 Cloud Dataproc
Cloud Dataproc 是 Google 去年 (2016) 推出的服務,讓使用者可以更快、更方便的管理 Hadoop 與 Spark。建置叢集不再需要煩雜的設定,只要透過網頁介面或是 gcloud dataproc 指令,幾分鐘的時間就能完成。Hadoop 與 Spark 的環境與工具都已預先設定,直接就能送出工作 (Job) 開始 Map-reduce 計算。至於收費方面,根據實際使用的 vCPU 數量計費,最便宜的機器每小時 0.01 美元 / vCPU,還可以選擇先佔工作站節點 (Preemptible VM Instances) 更進一步降低成本。
Cloud Dataproc 提供更簡易的介面,讓建制更快速,成本更低廉。圖 / Google
透過網頁介面建置
在 GCP 側邊欄,找到巨量資料下的 Cloud Dataproc ,點選建立叢集
試玩的話採用預先設定即可,不過要注意免費額度只提供 8個 vCPU,預設 master 4 vCPU 加上 worker 4 vCPU x2 會超過,需要稍微調整。而依照範例的設定,屆時會在 Google Compute Engine 開三台虛擬機,以 cluster_name-type 命名,整個 Cluster 的管理會在 Google Cloud Dataproc 的叢集面板中出現。
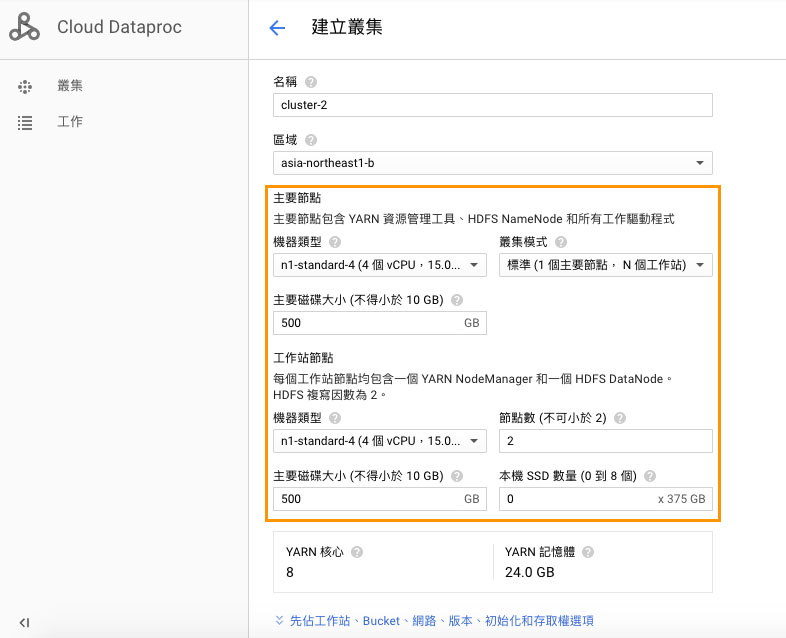
在 Cloud Dataproc 中建立叢集。圖 / 截圖自 Dataproc Console
點選上圖下方藍色文字 (先佔工作站、Bucket…)展開更多詳細設定。
- 先佔工作站 (Preemptible VM Instance) 的費用較低,最多只會持續運作 24 小時,是由系統自行管理其運作,調派多餘或閒置的機器來服務。
- 映像檔版本:指的是 Dataproc 版本,目前預設為 v1.1。預裝的套件版本分別有 Spark 2.0.2,Hadoop 2.7.3,Pig 0.16.0,Hive 2.1.0
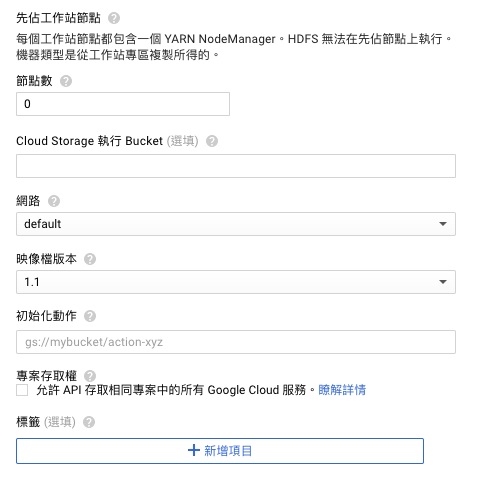
在 Cloud Dataproc 中建立叢集 (進階設定)。圖 / 截圖自 Dataproc Console
透過指令建立叢集
使用 gcloud 就能建置囉,透過 clusters create 指令建立預設叢集
gcloud dataproc clusters create下方的指令則是在區域 asia-east1-a 建立 4台 n1-standard-1 (1 vCPU, 3.75 G) 規格的 VM,其中一台為 master 剩下三台是 worker。
gcloud dataproc clusters create cluster2 \
--master-machine-type n1-standard-1 \
--worker-machine-type n1-standard-1 \
--num-workers 3
--zone asia-east1-a詳細的指令用法請看 gcloud dataproc 說明
備註:想要知道目前使用多少 vCPU額度 (Quota),需要透過 describe 指令。如下圖,最多 8 個已使用 6個 vCPU。
gcloud compute regions describe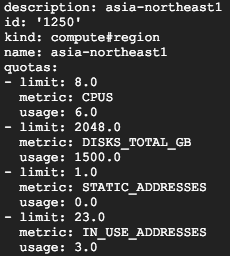
asia-northeast1 區域中,CPU限額為 8 個,目前已使用 6 個
透過 SSH 連線進入 master VM
在叢集詳細資料中,點擊 SSH 按鈕,開啟 Terminal 後直接下 hadoop 指令吧!你會發現環境已經幫你設定好囉
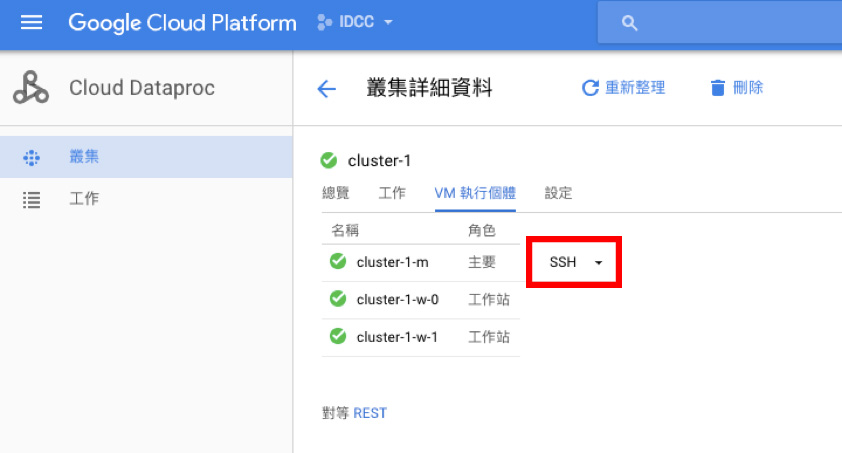
在 Cloud Dataproc 中透過 SSH連接 master instance。圖 / 截圖自 Dataproc Console
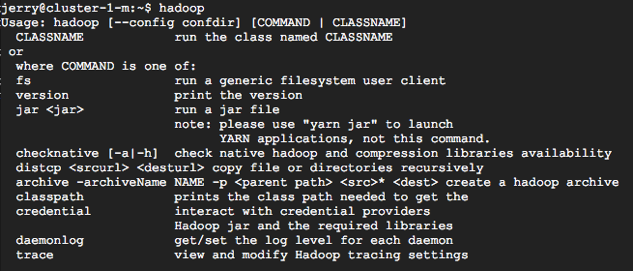
預設的 Hadoop與 Spark Home 分別如下,也順便記錄個 Hadoop Streaming jar 位置
HADOOP_HOME=/usr/lib/hadoop SPARK_HOME=/usr/lib/spark STREAMJAR=/usr/lib/hadoop-mapreduce/hadoop-streaming-2.7.3.jar
手工建置…
如果想要自己架設 Hadoop Cluster,體驗一下複雜的設定,那麼可以參考我以前的文章 (Hadoop 2.6.0)
如何在 Ubuntu14.04上安裝 Hadoop2.6.0


Jerry,您好,我最近也才開始使用這套,在安裝上都沒什麼問題,不過我遇到兩次是由google告知我利用這個進行了挖礦的動作,暫時先把我兩個工作站關掉,之後我去查看發現兩個工作站再執行的時候cpu會增長到100%甚至超過,再仔細看內容發現是yarn再一直做執行,這個部份我有先把機器停了再做啟動,但還是一樣cpu持續100%的狀態,我想請問一下這個部份不曉得您有遇到過嗎??
Hi Corki,
我之前沒有遇過這樣的情況耶, 會不會是你的工作量太大、資源開太小而導致 CPU high 呢?
恩~~基本上我除了工作站的部分設定4vCPU以外其他設定都是照著預設走,因為工作站它預設切兩個,這樣的話會用到主節點+2個工作站就用去12vCPU,不增加費用的話它基本配置就是給我們用到8vCPU,有沒有可能我工作站只個給2vCPU的關係才導致的能??另外我是建起來之後觀察CPU的狀況,在還沒執行任何程式的情況下它就會從大概5~60%上升到100%以上
Hi Corki,
還沒執行任何程式就 CPU High 是有點怪 >< 我開了主節點 (2vCPU)+2個工作站(各2vCPU),其他配置採用預設值,在 idle 狀態下 CPU 用量不會超過 5%。 會不會你的環境裡有 Job 還沒執行完?或是虛擬機中有其他程式在跑?試試重新用 dataproc 部署看看
Hi Jerry:
我這邊想確認一下在建立這樣的環境的時候自己電腦有在執行程式或者操作的話會影響雲端的機器嗎??應該是不會,環境裡有Job還沒執行完其實我有想過,所以我才刪除重新用dataproc部屬,一樣出現我昨天敘述的狀況,那我在使用top去觀察使哪個忽然巨量的在使用cpu發現是yarn會一直做執行。
Hi Jerry:
我這邊發現可能的原因,我在選擇區域的時候我選擇了asia-east1,之前都是用這個在做建構,今天想說換個區域看看一樣是asia區就不會發生此狀況,今天觀察下來是沒特別飆高的時候,這幾天會再多做觀察。
Hi, Corki
在自己電腦做事對遠端環境應該是沒有影響,就像你說的,感覺比較像是 GCP 的問題 QQ
不過我剛剛測試用的是 asia-east1-a,跑起來 CPU 正常,不知是否真的是區域造成的影響~
如果還有問題,可能要回報 issue 了
Hi Jerry
我這邊有做一個測試然後這兩天做了觀察,發現我有執行一個spark-submit,它去呼叫一個jar,這個jar我結尾沒做stop yarn的動作,那時我想說有可能是這樣導致yarn讓cpu 100%,但後來我有去檢查有沒有正在執行的yarn,發現沒有正在執行的但yarn卻還是跑100%以上甚至快到200%,這時我有個疑問,當我把正個dataproc刪掉,然後重建全新的不執行任何項目,為何它的yarn還會持續讓cpu上升到100%呢??難道那個區域已經記錄我這個使用者曾經操作過什麼事情嗎??當然這件事情是我想像的應該不會這麼神奇拉~哈
Hi Corki,
這還真的有點神奇XD 我在想會不會是吃預設 config 的問題,可能資源本來就不夠了?
剛好看到有人用 FairScheduler 來分配資源,給你參考一下:https://stackoverflow.com/questions/33458063/why-does-vcore-always-equal-the-number-of-nodes-in-spark-on-yarn
如果不行的話,用監控工具 Stackdriver monitoring 看看能否發現一些端倪
https://cloud.google.com/dataproc/docs/guides/stackdriver-monitoring
Hi Jerry,
這邊我有發現倒其實在啟動yarn的時候就會開始讓cpu一直升高到100%我不確定是否我按照網路上的設定有沒有問題,但我看到大概啟動10鐘左右,它就會有個dr.who的預設一直在嘗試在做事情,平均下來就是每10秒就會做一次,因為一直fail的關係所以他會一直做一直做,這期間我自己建了三個VM master slave1 slave2一步步安裝hadoop 2.7.6 spark 2.1.1 scala 2.12.1的版本
Hi Corki, dr.who 是預設的使用者,這麼看起來就是預設的設定上出問題了😂
不知道這篇文章的方法能否順利解決
https://my.oschina.net/MIKEWOO/blog/1542194
Hi Jerry
感謝您提供這麼多相關連結給我,這邊我在啟動yarn時,看了一下錯誤訊息
Application application_1529892107937_0001 failed 2 times due to AM Container for appattempt_1529892107937_0001_000002 exited with exitCode: 0
For more detailed output, check application tracking page:http://master:8088/cluster/app/application_1529892107937_0001Then, click on links to logs of each attempt.
Diagnostics: Failing this attempt. Failing the application.
我在想一件事情就是我們透過雲端見出來的vm他的hostname的問題,按照裡說我名稱設定master好了,所以他會有一個http://master:8088這樣可以連過去,這個我在用一般VM給hostname的時候連線是沒問題的,在/etc/hosts裡面我也有做設定,那在雲端這塊其實我有點疑惑,這個雲所設定的hostname究竟有沒有效果??,我用http://master:8088是無法直接連線過去的,唯一個連線方式是用外部IP才可以連通,那因為hadoop這些設定都是直接設定hostname所以他在啟動的時候確實有抓到我所做的ssh設定連線所以連的通,但在用http的時候用了hostname卻是失敗