在上篇文章中,練習了範例程式 Word count 的使用,以及學習如何操作 HDFS。接下來這個例子,增加了一點變化,要來分析Apache 2 web server 的 log 記錄檔,計算每小時的存取次數。以下使用 Python,如果想要使用 Java,可以參考這篇文章
實作分析
首先,要了解 Apache2 web server 記錄檔的格式長怎樣。可以參考官方的說法,也可以看看下面的例子。Apache2 web server 的檔案格式如下:
64.242.88.10 - - [07/Mar/2004:16:10:02 -0800] "GET /mailman/listinfo/hsdivision HTTP/1.1" 200 6291
這裡面包含了來源 IP 位置,時間以及 HTTP Request 資訊。
由於我們要算的是每小時的存取次數,IP 位置與 Request 資訊都可以拿掉,只留下時間,如下:
2004-03-07 T 16:00:00.000
所以要做的事情是:擷取框框中的時間字串,將分與秒清空為 00,接著丟進 Hadoop 算 Word count,等待結果
MapReduce 範例程式
這是根據網路上的 Python範例程式修改而成,有興趣可以參照 這篇教學
mapper.py
#!/usr/bin/env python
import sys
import time
import datetime
# input comes from STDIN (standard input)
for line in sys.stdin:
# remove leading and trailing whitespace
line = line.strip()
words = line.split('[')
words = words[1].split(' -0800')
time = datetime.datetime.strptime(words[0], "%d/%b/%Y:%H:%M:%S")
print time.strftime('%Y-%m-%d T %H:00:00.000')+"\t1"reducer.py
#!/usr/bin/env python
from operator import itemgetter
import sys
current_word = None
current_count = 0
word = None
for line in sys.stdin:
line = line.strip()
word, count = line.split('\t', 1)
try:
count = int(count)
except ValueError:
continue
if current_word == word:
current_count += count
else:
if current_word:
print '%s\t%s' % (current_word, current_count)
current_count = count
current_word = word
if current_word == word:
print '%s\t%s' % (current_word, current_count)範例 access.log檔案下載(已移除)
手邊沒有 Apache log 的話,可以拿 NASA 提供的 HTTP 資料集做測試 連結:NASA-HTTP (裡頭的時區是 0400,需要改一下程式才能跑喔)
程式解說
擷取框框中的時間字串,並濾掉-0800
line = line.strip()
words = line.split('[')
words = words[1].split(' -0800')得到這樣子的輸出
07/Mar/2004:16:10:02
接著透過 Python 的 datetime module 來做格式的轉換
time = datetime.datetime.strptime(words[0], "%d/%b/%Y:%H:%M:%S")
print time.strftime('%Y-%m-%d T %H:00:00.000')+"\t1"表格中節錄幾個用到的符號:
| Directive | Meaning | Example |
|---|---|---|
| %d | Day of the month as a zero-padded decimal number. | 01, 02, …, 31 |
| %b | Month as locale’s abbreviated name. | Jan, Feb, …, Dec (en_US);Jan, Feb, …, Dez (de_DE) |
| %m | Month as a zero-padded decimal number. | 01, 02, …, 12 |
| %Y | Year with century as a decimal number. | 1970, 1988, 2001, 2013 |
| %H | Hour (24-hour clock) as a zero-padded decimal number. | 00, 01, …, 23 |
| %M | Minute as a zero-padded decimal number. | 00, 01, …, 59 |
| %S | Second as a zero-padded decimal number. | 00, 01, …, 59 |
為了要交給 MapReduce 去統計次數,必須要將每小時的資料修改成一樣
這裏輸出單位至小時,後面的分秒都設為 0,並在後面加上一個 1,結果如下:
2004-03-07 T 16:00:00.000 1
PS. 因為只是要統計次數,其實可以不要印出 0,這邊只是參考網路上 Java 版本的作法,做相同的輸出
在執行 Hadoop MapReduce 前,我們先執行看看 Python 程式是否正確
$ cat access.log | python mapper.py | python reducer.py
在 Hadoop 上進行運算
先將 Hadoop 開起來
# clear tmp, hdfs file rm -r tmp hdfs # format hdfs system hdfs namenode –format # starting Hadoop service /opt/hadoop/sbin/start-all.sh
執行 MapReduce
這邊我寫了一個 Script,並附上註解了,如果還是不清楚,可以參考 Hadoop Streaming 的說明
#!/bin/bash
# Hadoop stream jar
STREAMJAR=/opt/hadoop/share/hadoop/tools/lib/hadoop-streaming-2.6.0.jar
# input file
INPUT=access.log
# input directory
INPUT_DIR=/input
# output file
OUTPUT=result.dat
# output directory
OUTPUT_DIR=/output
# mapper file
MAPPER=./mapper.py
# reducer file
REDUCER=./reducer.py
# create input directory on hdfs
hdfs dfs -mkdir /input
# upload input file to input directory
hdfs dfs -put $INPUT $INPUT_DIR
# remove old output directory
hdfs dfs -rm -r -f $OUTPUT_DIR
# execute map-reduce with Hadoop stream jar
hadoop jar $STREAMJAR -files $MAPPER,$REDUCER -mapper $MAPPER -reducer $REDUCER -input $INPUT_DIR -output $OUTPUT_DIR
# download the output file from hdfs
hdfs dfs -cat $OUTPUT_DIR/part* $OUTPUT檔案存放在 output 資料夾下

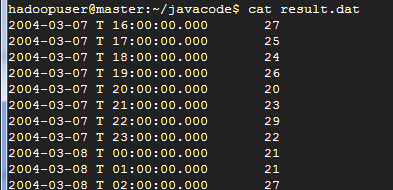
執行結果
打開 result.dat 檔案,就可以看到結果拉