之前曾介紹過微軟的免費機器學習服務 Machine Learning Studio,他擁有方便的圖形化介面,對於使用來說,建置模型變得更容易、更直覺。相比兩巨頭 Google、Amazon 推出的機器學習服務,Google Cloud Machine Learning 目前仍需要透過指令操作,而 AWS 則是沒有免費額度提供試用。
一直到最近 (註),這個心願終於被滿足啦!聽完由 AWS 技術傳教士帶來的 Machine Learning Workshop,短短兩小時就快速上手。不僅如此,活動附有點心、飲料以及 25 美元的體驗額度,跑完範例還剩很多錢耶。本文就記錄一下所見所聞,根據範例的 Bank Marketing Data Set 示範一下囉。
註: 最近指的大概是 4 月吧,很久以前了,這篇文章拖到現在才補完發表哈哈
AWS 機器學習
Amazon Machine Learning 是將 Amazon 以往用在商城的引擎包裝成服務,讓使用者可以直接使用優化過後的模型,免去煩人的參數調校。你可以透過 S3、Lambda、MySQL 等方式匯入資料,解決 Binary、Multi-class 以及 Regression 這三種問題。除了批次預測外,訓練後的模型也可以打包成 API 進行即時預測 (會產生額外費用)。優缺點如下:
優點
- 專為開發人員打造,簡單好用
- 不需要特別去選擇演算法 (基於 Logistic Regression + SGD)
- 可以訓練高達 100 GB 的數據
- 能與 AWS 相關服務結合 (S3, Redshift, RDS, EMR, Lambda)
- 短時間即可完成部署並上線
缺點
- 只有一種演算法
- 只支援三種預測類型 (Binary, Multi-class, Regression),目前無法做 Clustering
機器學習三步驟
在 AWS上使用機器學習服務相當簡單,三個步驟透過網頁操作即可輕鬆完成。
- 訓練模型:目前只支援 CSV 格式,請先確保資料都清洗乾淨了
- 評估與最佳化:預設使用 70 % 訓練,剩下 30 % 評估,可以對比例進行微調,或用新的資料做評估
- 取得預測結果:提供批次預測與即時預測,即時預測需要先開 Real-time Endpoint (會有額外費用產生)
取得範例資料集 Bank Marketing Data Set
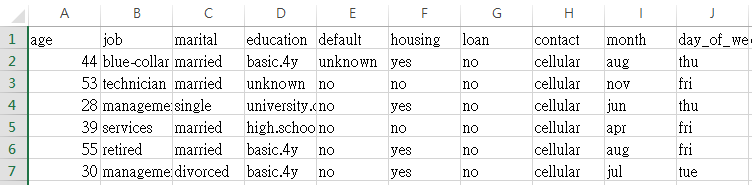
我們使用的是 UCI 的 Bank Marketing Data Set ,這個資料集與葡萄牙銀行機構的電話行銷有關,想知道客戶會不會在他們銀行定期存款。透過機器學習建立模型之後,我們能根據過往經驗,輕易判斷客戶在銀行定期存款的機率,這麼一來,就可以集中火力打電話給那些機率高的客戶,提升整體業績。
資料位置如下,跟普通的資料集沒什麼兩樣,最後一欄是 Label,代表該客戶會不會定期存款。
https://s3.amazonaws.com/aml-sample-data/banking.csv
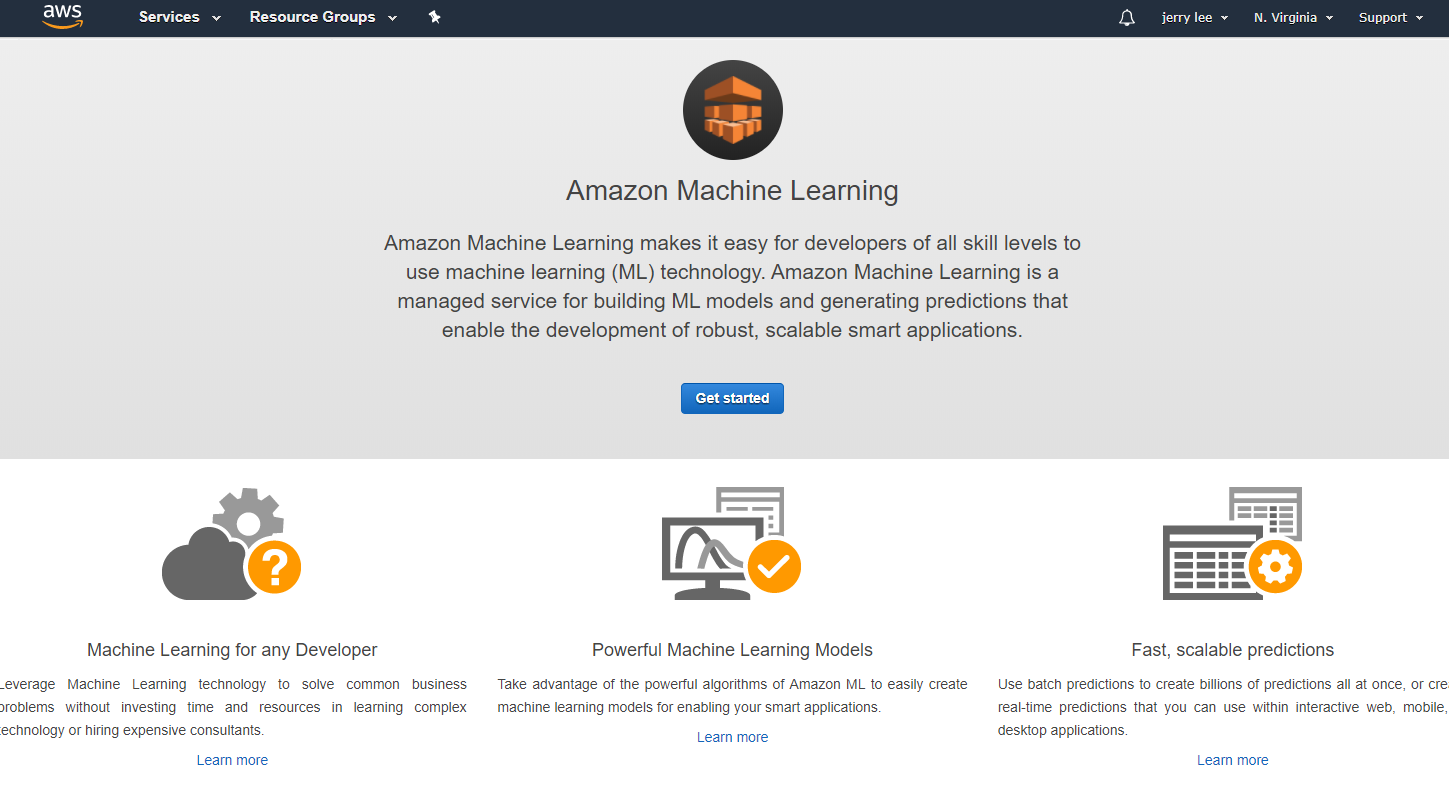
開始你的 AWS 機器學習之旅
Hello world,讓我們開啟 AWS Machine Learning Console,點選「Get Started」
https://console.aws.amazon.com/machinelearning
使用標準的設定,點選「Standard setup」右方的「Launch」
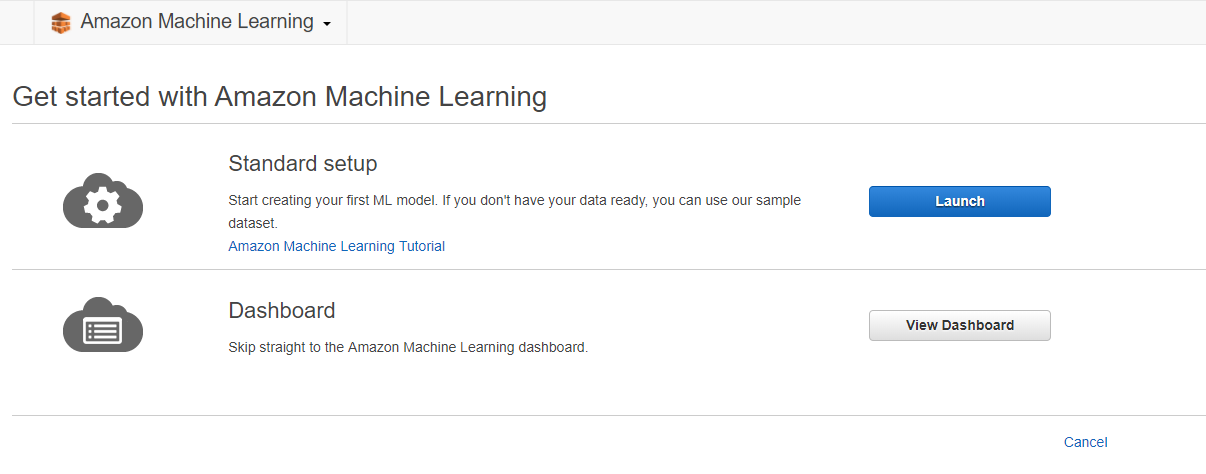
使用雲端服務,當然就是要把資料丟上去才能計算拉,直接丟 S3 就行了,他跟 Google Cloud Storage 相同,需要建立 Bucket,不過針對範例教學,AWS 已經在 S3 提供樣本資料,直接貼上他提供的位置即可。點選「Verify」驗證資料,會檢查 Schema 有沒有錯誤,同時偵測資料類型,沒問題就可以進入下一步了。
s3://aml-sample-data/banking.csv
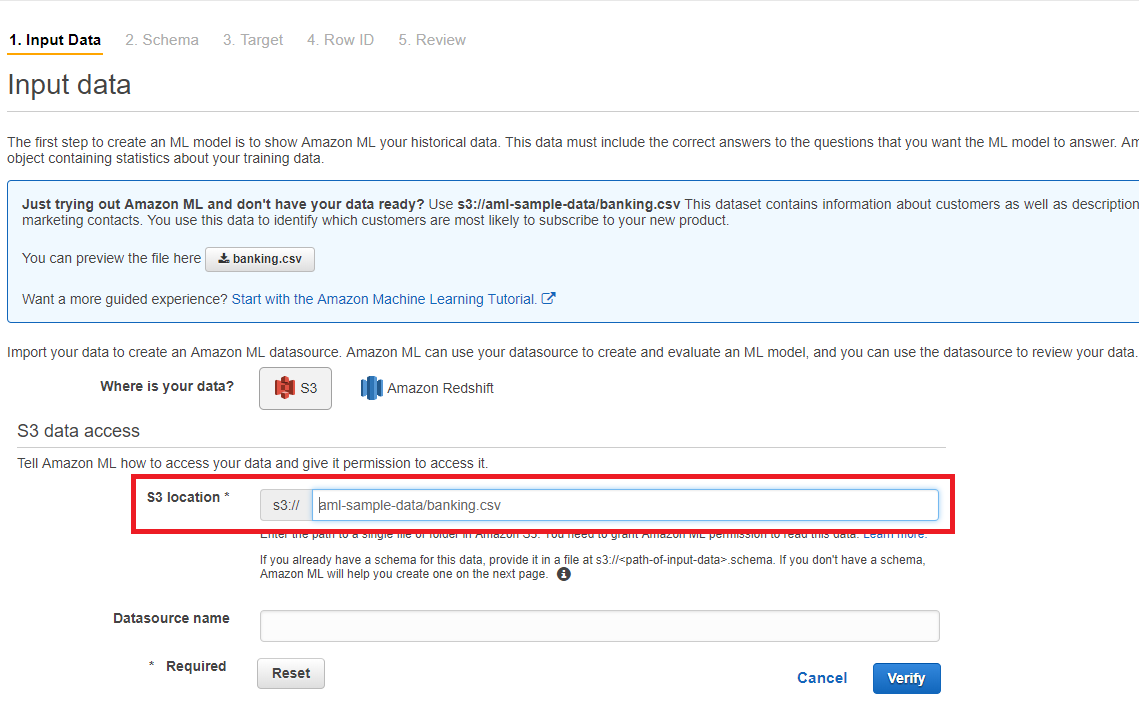
會根據資料自動判斷資料型態,基本上都會對拉,保險起見還是要檢查一下,特別是 Label,假如是 Binary Classification 問題,那資料型態應該要是 Binary。
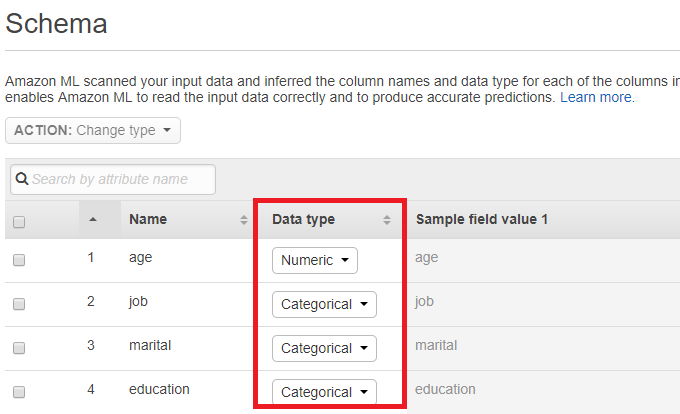
接著會與你確認要用那一項特徵當作 Label,也就是這裡說的 Target。範例使用的是最後一欄「 y」。
沒甚麼問題的話,就可以一直下一步,完成資料上傳,他會開始做資料前處理。這部分要等個幾分鐘,我覺得有點久,不過沒關係,這不影響機器學習模型的設定。
設定機器學習模型
根據 AWS 技術傳教士的說法,AWS 有多年的機器學習經驗,已經把這套系統優化過了,你只需要丟資料上來,選擇預設模型,剩下的 AWS 幫你做得好好,就相信他們吧 xddd
依照預設選項,資料會切成 70 % 與 30 %,分別用於訓練與驗證,假如你不喜歡這個比例,可以選右邊的「Custom」自行調整。
沒問題的話,預設模型就會直接拿 30 % 跑驗證,所以送出之後,就等結果囉。
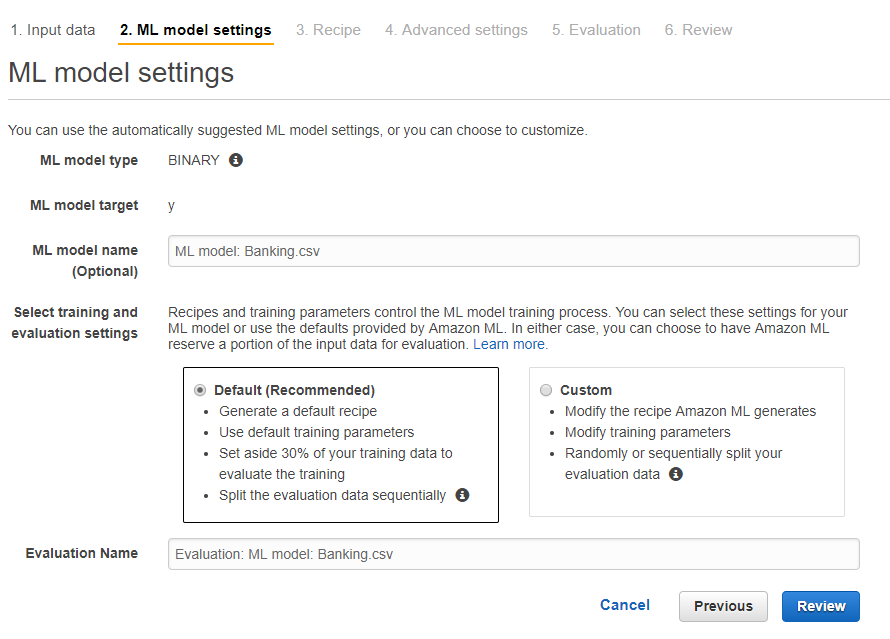
在 Amazon Machine Learning 主控台的「Data sources」中,你可以看到資料正在處裡中 (in progress),會先做完前處理,接著再把資料切兩份。
因為資料還沒處理完,所以「ML model」這邊是 pending 狀態。
讓他跑一會兒,我們就能看見成果了。
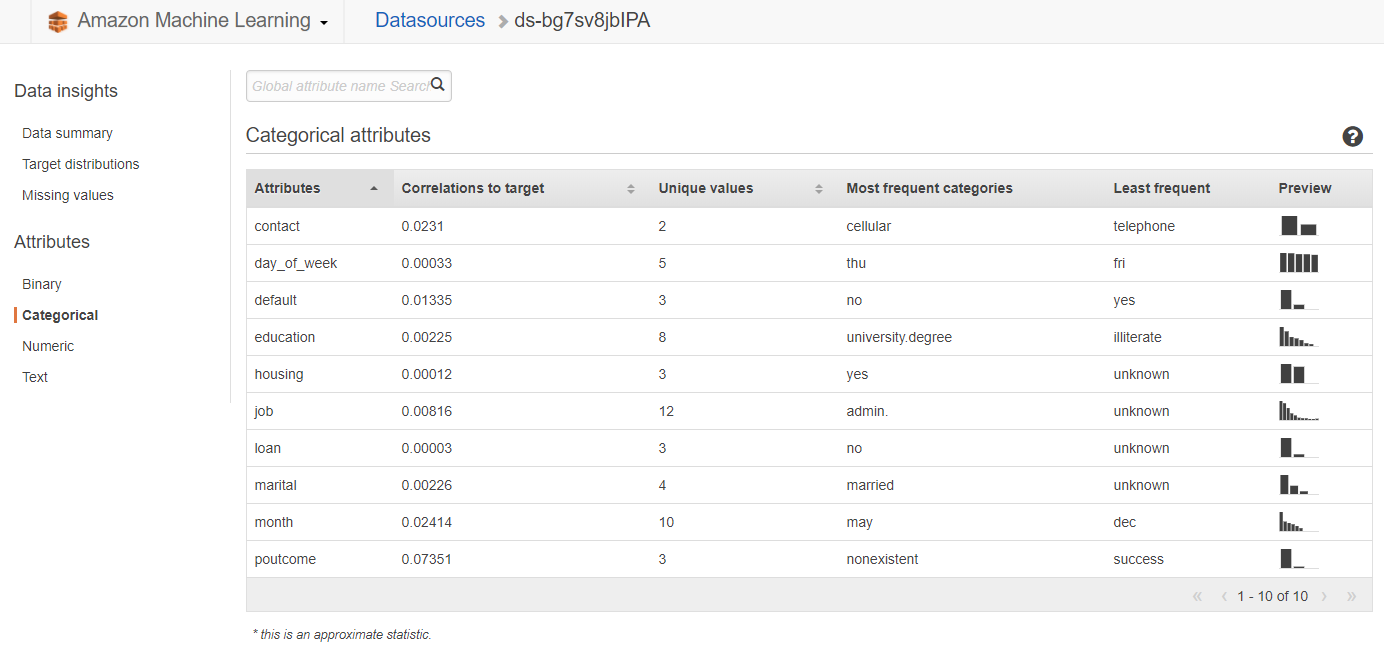
首先來看看資料前處理處理得如何。點選「Datasources」分頁,資料都已經匯入進來了,而且還幫你做簡單的分析與視覺化 (這也是為什麼前面要跑這麼久的原因 …)
點選「Evaluation」能看到驗證結果,還有一張貼心的圖 😎 你可以根據誤判率、準確率等指標去調整 threshold,讓模型最佳化。
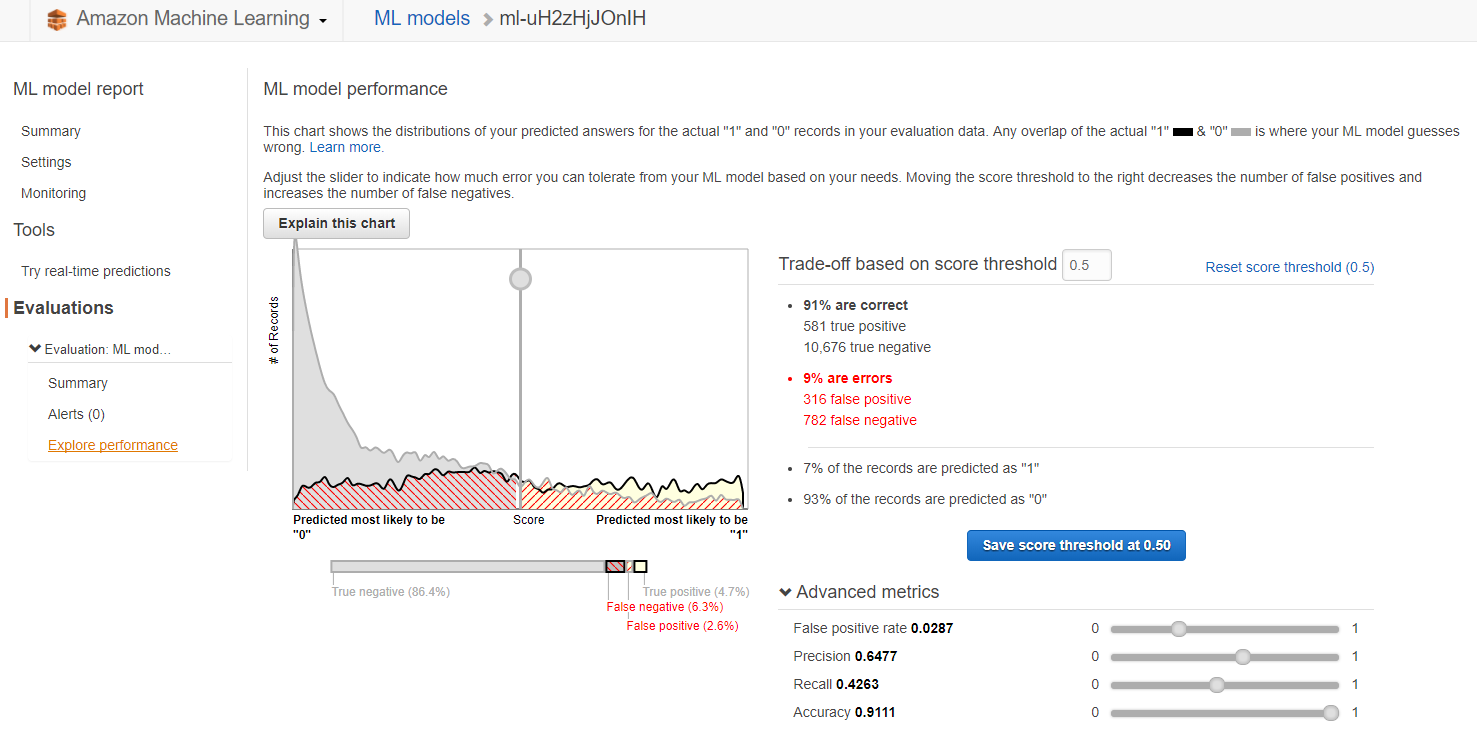
假如你不知道要怎模調整,AWS 提供了一張圖做說明。我個人是覺得在交集區域調整而百分比只差一點點,調這個 threshold 意義就不大啦,大概就行,因為機器學習出來的結果是機率呀,這僅是用驗證資料在調參數,難保真實或其他資料進來又會有變化。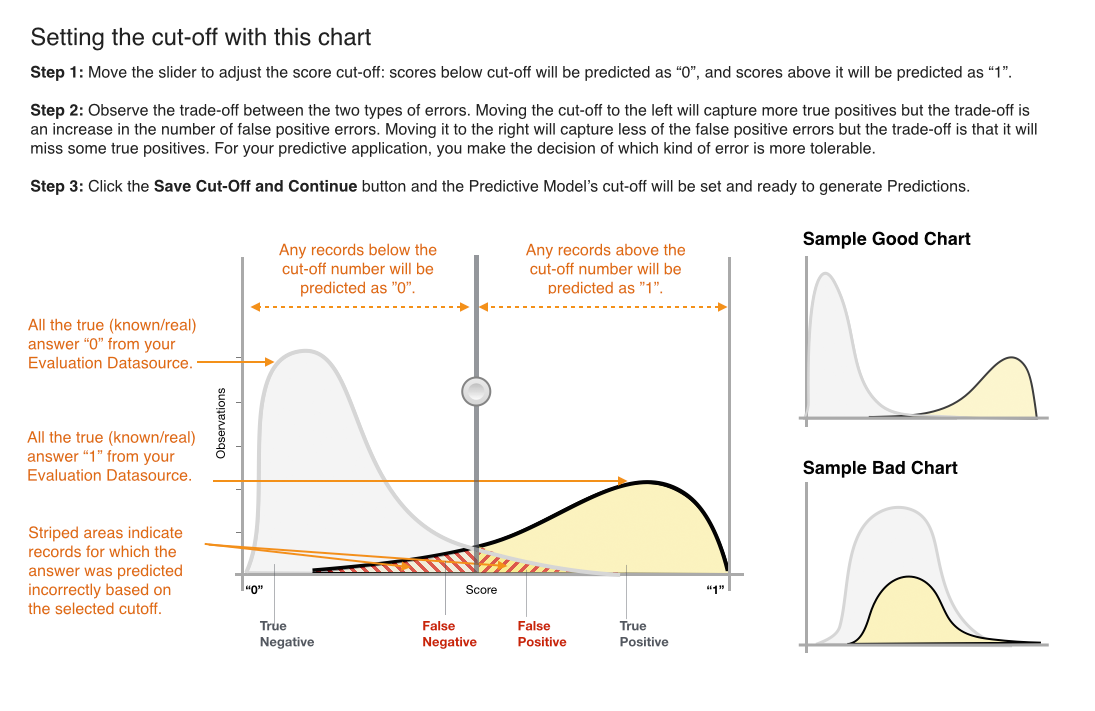
輸出你的模型,讓我們來預測即時資料吧
在「Tool」分頁中,選擇「Try real-time predictions」就可以模擬發送 Request 並取得預測結果。當然這個頁面只是讓你試試看,實際上我們要開一個端點,並透過 AWS 提供的 SDK 進行呼叫。
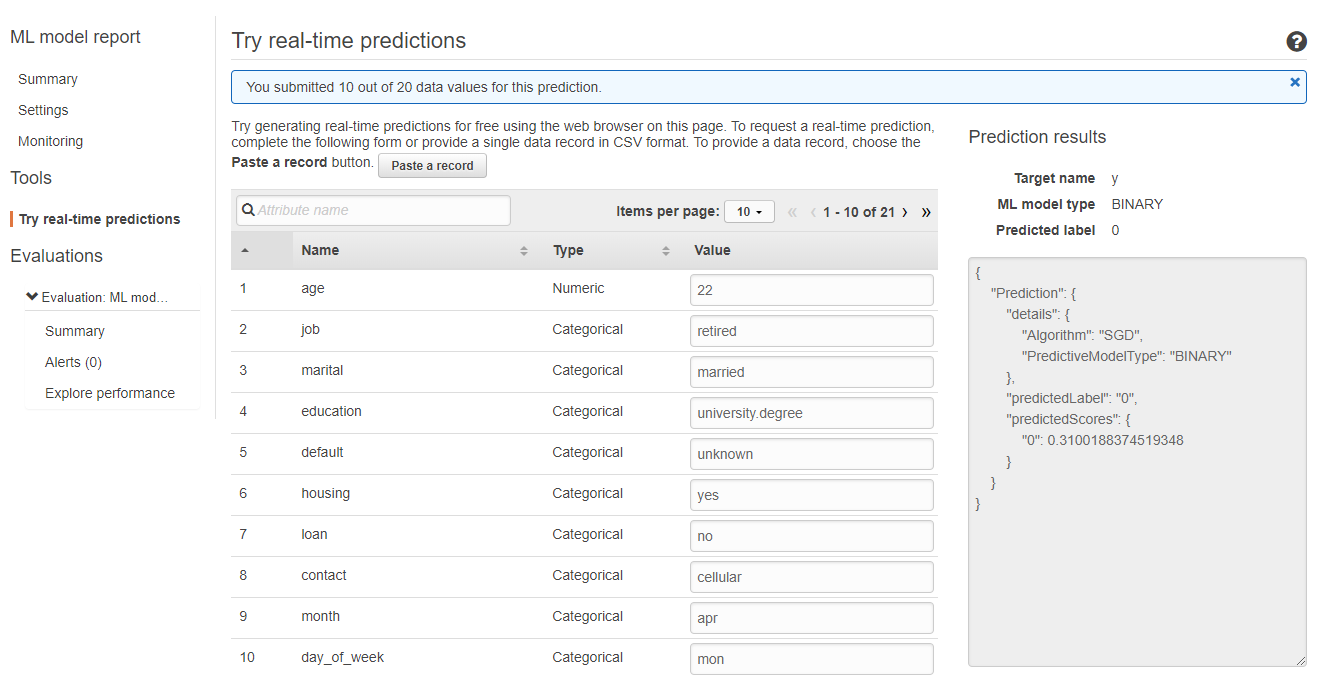
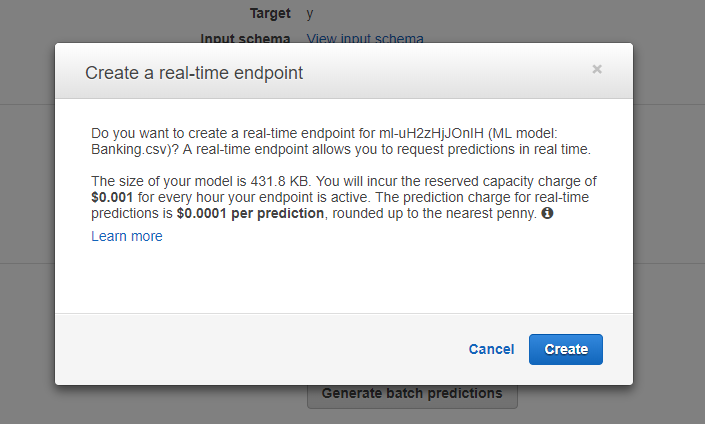
在「Model Setting」中,開啟即時預測的端點,點選「Create endpoint」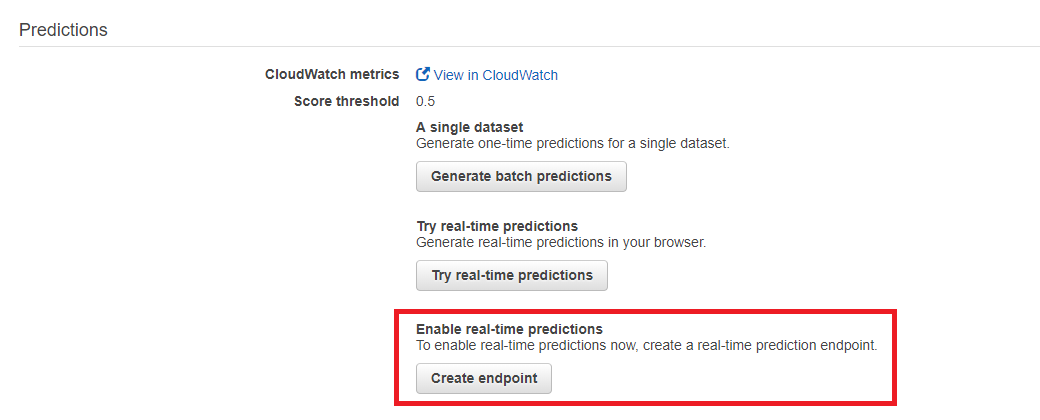
在建立端點的同時,會告知你這項服務得計費方式,每呼叫 10000 次收取 1 元美金。
這裡就省略 SDK 串接的使用方式,詳細內容請參考 AWS 說明文件以及其他網友的教學。
Amazon Machine Learning API Reference - Predict
底下這是 AWS 官方的教育推廣簡報,也可以參考看看
參考資料
Tutorial: Using Amazon ML to Predict Responses to a Marketing Offer