之前實作 ETL 系統是透過 Python + MongoDB/MySQL 完成,對於少量的資料綽綽有餘,但如果想處理大量資料,又想要借用 Spark MLlib 機器學習套件的話,那麼就使用 PySpark + Hive 來達成任務吧。能使用熟悉的 Python 與 SQL 語法,無痛轉移。
Spark 與 Hive 環境設定
這裡透過 Google Cloud Dataproc 架設,Cluster 跑起來之後全部套件都有囉,包含 Hadoop 2.7.3,Spark 2.0.2 與 Hive 2.1.1 ,而為了要使用 PySpark,記得加上環境變數。
$ export SPARK_HOME=/usr/lib/spark
$ export PYTHONPATH=$SPARK_HOME/python:$SPARK_HOME/python/build:$PYTHONPATH
使用 PySpark 來進行 ETL

ETL 的流程就如上圖三步驟。我們想要抓取的資料是行政院農委會提供的 農村地方美食小吃特色料理,內容是農村特色料理的所在位置與店家資訊,反正內容是什麼不重要,重要的是希望程式能直接透過 HTTP Request 抓下來,經過轉換後丟進 Hive 資料庫。 由於 Spark 2.0 版本加入了 Spark Session,使用上變得簡潔,不過想要與 Hive溝通,記得要加上 enableHiveSupport() 才能存取資料喔。另外,Dataproc 上的 Python 版本為 2.7,處理中文會比較麻煩,如果要換成 Python 3,記得 Cluster環境下只改 Master是不行的,必須要在裝環境的時候,將 所有機器上的 PySpark 預設改掉。詳細作法可以參考這篇。這裡仍然使用 Python 2.7,詳細的程式碼與說明如下:
# -*- coding: utf-8 -*-
from pyspark.sql import SparkSession
from pyspark.sql import HiveContext
import requests
import json
class SparkHiveExample:
def __init__(self):
## initialize spark session
self.spark = SparkSession.builder.appName("Spark Hive example").enableHiveSupport().getOrCreate()
def run(self):
## download with opendata API
url = "http://data.coa.gov.tw/Service/OpenData/ODwsv/ODwsvTravelFood.aspx?"
data = requests.get(url)
## convert from JSON to dataframe
df = self.spark.createDataFrame(data.json())
## display schema
df.printSchema()
## creates a temporary view using the DataFrame
df.createOrReplaceTempView("travelfood")
## save into Hive
self.spark.sql("DROP TABLE IF EXISTS travelfood_hive")
df.write.saveAsTable("travelfood_hive")
## use SQL
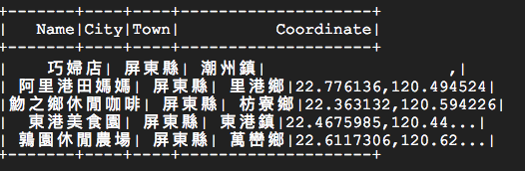
sqlDF = self.spark.sql("SELECT * FROM travelfood_hive WHERE City == '屏東縣'")
sqlDF.select("Name", "City", "Town", "Coordinate").show()
if __name__ == "__main__":
EXAMPLE = SparkHiveExample()
EXAMPLE.run()
從 Requests 取得的 JSON 格式資料,使用 createDataFrame 就會變成 Spark的 DataFrame 格式,也因為這個資料集的 Key 只有一個層級,轉換不用特別處理,你能透過 printSchema 看見所有的欄位名稱。 使用 createOrReplaceTempView 會產生一個暫時的 View,就能透過 SQL 語法存取資料了,但注意資料還沒有送進 Hive 喔,只是方便你處理而已,必須用 DataFrame 的函式 saveAsTable 才算完成。剩下的 SQL 操作,看看就懂了吧!附上執行結果:
Youtube 上的教學影片
如果使用的語言是 Scala,請參考這部影片的教學 (Spark 1.6)

若需要config Mongo DB(這個nosql 類市占率第一),可以參考此url http://www.runoob.com/mongodb/mongodb-linux-install.html 來簡易安裝
另外檢查spark 上是否可run python 的pyspark 互動介面,也可以參考這個url http://pythonsparkhadoop.blogspot.tw/2016/09/8-spark-20.html