知道如何抓取個股歷史資料後,接著就是透過股票列表來捉所有股票資料囉。
我們可以到證交所網頁上找到這個「本國上市證券國際證券辨識號碼一覽表」,但因為東西太多了,開網頁的時間可能會有點漫長 (Q),連結如下:
http://isin.twse.com.tw/isin/C_public.jsp?strMode=2
爬蟲程式
使用 Python3 結合 Requests 與 BeautifulSoup 套件進行截取。
import requests
from bs4 import BeautifulSoup
def getList():
url = "http://isin.twse.com.tw/isin/C_public.jsp?strMode=2"
res = requests.get(url, verify = False)
soup = BeautifulSoup(res.text, 'html.parser')
table = soup.find("table", {"class" : "h4"})
c = 0
for row in table.find_all("tr"):
data = []
for col in row.find_all('td'):
col.attrs = {}
data.append(col.text.strip().replace('\u3000', ''))
if len(data) == 1:
pass # title 股票, 上市認購(售)權證, ...
else:
print(data)
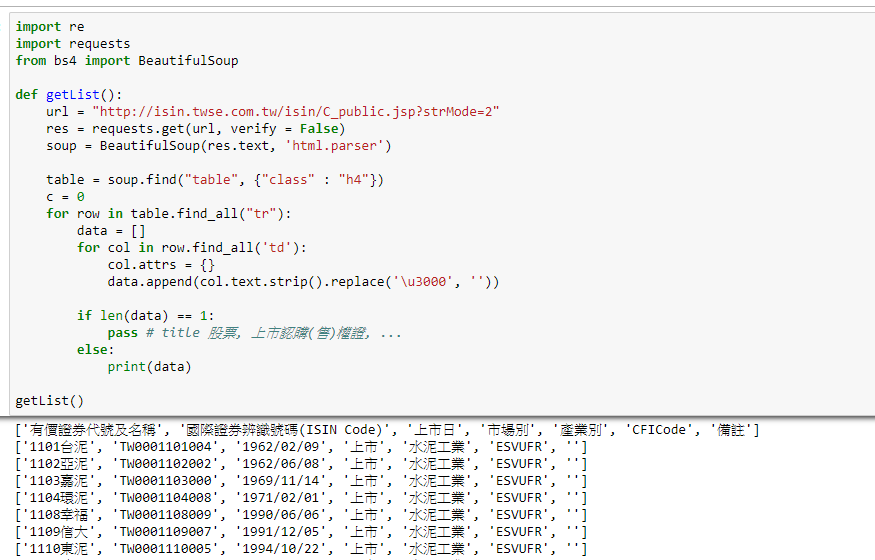
getList()程式執行截圖

Jerry 您好
我在Macbook上用Jupyter 可以執行, 但是在測試的Docker環境裡, 陸續有安裝requests, BeautifulSoup module 但仍遇到下面的訊息,可能是抓取資料時,有中文,所以print(data) 會有錯誤,請問這是要先轉編碼再print嗎? 謝謝。
root@9bf88a7b1c93:/tmp# python3 get_stock_number.py
Traceback (most recent call last):
File “get_stock_number.py”, line 25, in
getList()
File “get_stock_number.py”, line 23, in getList
print(data)
UnicodeEncodeError: ‘ascii’ codec can’t encode characters in position 2-10: ordinal not in range(128)
Hi Jim,
應該是編碼的問題,可以試試看這個
https://stackoverflow.com/questions/20923663/unicodeencodeerror-ascii-codec-cant-encode-character-in-position-0-ordinal
我照著這個範例執行
程式到了 data = re.search(r ‘(.*) (.*)’, col1)
就會中斷,請問格式哪邊有誤呢?
Hi, Pei Hsun
網頁格式改過了,看來舊的 code 已經不能跑了
我用 python3 更新囉