這隻程式的起因 … 全來自於想買到蘇打綠演唱會門票呀
注意:本篇文章年代久遠 … 程式碼很慘,近期會更新
故事未了演唱會,是蘇打綠的韋瓦第計畫最終章。這次把整個交響樂團請來表演,以音樂會形式來呈現,感覺檔次向上提升不少,十分吸引人呀。可是可是,賣票當天 11:00,我居然在水深火熱之中,考演算法期中考阿…。下午 2:00 的釋出,看著圈圈轉呀轉,轉呀轉,回過神來已經銷售一空拉… 實在有夠搶手
就在我萬念俱灰之際,聽到學長這麼一說:「你要不要去爬 PTT 票卷交易版,很多人會在上面賣票喔,而且我朋友之前有寫程式去抓 PTT 文章耶,可以來做自動偵測」,於是乎…將目標鎖定在 PTT 的 Drama-Ticket 板,寫程式來自動偵測新文章!
爬 PTT 網頁版
使用 Python 來爬 PTT 網頁版,這邊用到兩個 Framework 以及 iPython 開發工具來加速開發,如下
- Requests (下載網頁)
- BeautifulSoup4 (解析 HTML)
- iPython Notebook
這些都透過 pip 安裝
$ pip install ipython[notebook]
$ pip install requests
$ pip install beautifulsoup4
程式碼 (Python 2.7)
# -*- coding: utf-8 -*-
import requests
import urllib2
import re
import smtplib
from bs4 import BeautifulSoup
from email.mime.multipart import MIMEMultipart
from email.mime.text import MIMEText
# drama-ticket url
url_ticket = "https://www.ptt.cc/bbs/Drama-Ticket/index.html"
# count = [page #, article #, target #]
count = [0,0,0]
def getFirstPage(count):
res = requests.get(url_ticket, verify=False)
first_page = re.search(r'href="/bbs/Drama-Ticket/index(\d+).html">‹', res.text).group(1)
count[0] = int(first_page)+1
def read():
file = open("log.txt", 'r')
read = file.read().strip().split("\t")
c=[int(read[0]),int(read[1]),int(read[2])]
file.close()
return c
def save(count):
file = open("log.txt", 'w')
file.write(str(count[0])+"\t"+str(count[1])+"\t"+str(count[2]))
file.close()
def getPage(count):
res = requests.get("https://www.ptt.cc/bbs/Drama-Ticket/index"+str(count[0])+".html", verify=False)
soup = BeautifulSoup(res.text,'html.parser')
count[1] = len(soup.select('.r-ent'))
count[2] = 0
ss=""
for entry in soup.select('.r-ent'):
s = entry.select('.title')[0].text.encode('utf-8')
if "" in s and "" in s:
#ss+= entry.select('.title')[0].text.encode('utf-8')
ss+= "<a href='https://www.ptt.cc" + entry.select('.title')[0].a.get('href').encode('utf-8′) + "'>"
ss+= entry.select('.title')[0].text.encode('utf-8')
ss+= "</a>"
count[2] = count[2] + 1
return ss
def email(string):
me = 'example@gmail.com'
you = 'example@gmail.com'
msg = MIMEMultipart('alternative')
msg['Subject'] = "蘇打綠演唱會門票-近況更新"
msg['From'] = me
msg['To'] = you
string = "
<h3>蘇打綠有新的票要被賣出, 趕快來看看!</h3>
" + string
html = MIMEText(string, 'html')
msg.attach(html)
gmail_user = 'example@gmail.com'
gmail_pwd = 'password'
smtpserver = smtplib.SMTP("smtp.gmail.com",587)
smtpserver.ehlo()
smtpserver.starttls()
smtpserver.ehlo()
smtpserver.login(gmail_user, gmail_pwd)
smtpserver.sendmail(me, you, msg.as_string())
smtpserver.quit()
getFirstPage(count)
string = getPage(count)
s_count = read()
if count[0] > s_count[0]:
s_count[1] = 0
s_count[2] = 0
if count[2] > s_count[2]:
#print "new"
email(string)
#print string
#print count[0], count[1], count[2]
save(count)
簡單說明:以下為 PTT 票卷網頁版的位置
https://www.ptt.cc/bbs/Drama-Ticket/index.html
直接打 index 看到的是最新一頁,檢查原始碼內的 URL,可以找到當前頁數
https://www.ptt.cc/bbs/Drama-Ticket/index(\d+).html
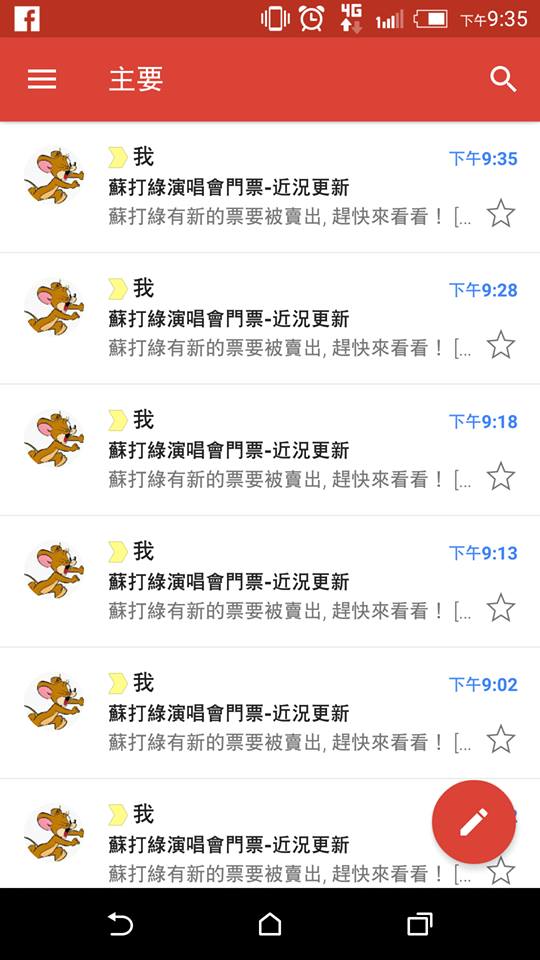
最後用 txt 檔案紀錄目前偵測到的頁數、文章數和相符的文章數,每當有新的相符文章 (標題字串包含”蘇打綠”與”售”),就會透過email 來寄信通知,大致像下圖這樣
有興趣的話歡迎參考我的其他文章