架設 Hadoop 對於新手來說,常會遇到很多莫名其妙的問題。這些問題,不外乎是版本不同、環境不同,或是對 Linux 指令不熟。
傑瑞也是過來人,當初在架設時遇到一些困難,所以想把架設的經驗寫下來,或許對大家有幫助。本文的內容會教大家如何在 Ubuntu 上佈署雙節點 Hadoop,並列出一些注意事項供參考。
準備工作
首先,準備兩台安裝好 Ubuntu 14.04 的測試機台(分別稱作 Master 與 Slave),並確認網路暢通。可以在自己的實體機架設或利用 Amazon、Google 等廠商提供的雲端服務來建立自己的虛擬機器。這裡,我使用 Google Compute Engine 提供的服務,在上面建立了兩台 Ubuntu 14.04 主機。
安裝流程
- 新增用戶與群組
- 設定網路
- 設定 SSH 連線
- 安裝 Java
- 安裝 Hadoop
- 設定 Hadoop
1. 新增用戶與群組
分別在兩台機器中,創建一個新使用者 hadoopuser,歸屬於 hadoopgroup 這個群組,並設定密碼
sudo addgroup hadoop
sudo adduser -ingroup hadoop hadoopuser
sudo passwd hadoopuser接著切換到 hadoopuser
su - hadoopuser加入 (-) 代表切換至 hadoopuser 根目錄
2. 設定網路
為了方便 SSH 連線,我們要先設定 hostname 以及 host list。 hostname 為主機名稱,也就是 terminal 下小老鼠 (@) 右邊顯示的名稱
打開 hostname 檔案,將一台改為 master,另一台改為 slave1
sudo vim /etc/hostname改完後請重新啟動電腦,讓設定生效
如果不想重開的話,可以使用 hostname 指令,做一次性的設定
sudo hostname masterhosts檔案放置 IP 與主機名稱的對應,這裡我填的是內網 IP 注意不要把原本的 localhost 唷
sudo vim /etc/hosts10.240.0.4 master
10.240.0.5 slave13. 設定 SSH 連線
master 使用 SSH 並透過金鑰認證,將工作分配給各個 slave 運算,因此我們要產生一組 key,做免密碼 SSH 登入。 首先,利用 Ubuntu 的 apt-get 在兩台電腦安裝 SSH (已安裝就可跳過)
sudo apt-get install ssh在 Master 產生一組 SSH key,產生完就會出現一個框框
ssh-keygen -t rsa -P ""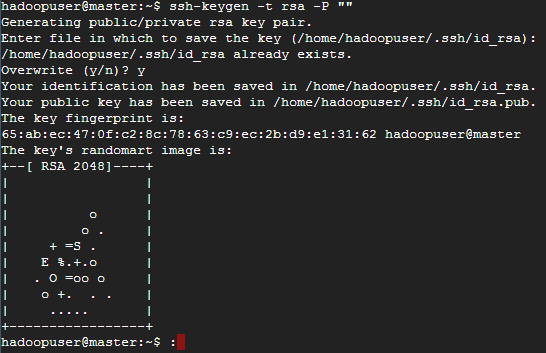
將公鑰複製給 slave1
cp ~/.ssh/id_rsa.pub ~/.ssh/authorized_keys
scp -r ~/.ssh slave1:~/
設定完後,用 master 試試可否連線至 slave1,成功的話就會看到 @ 後面變成 slave1 了
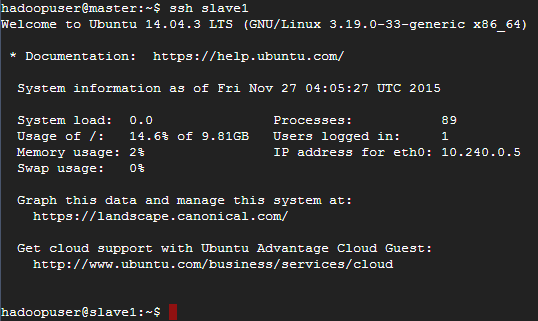
如果無法用 scp 複製金鑰,有可能系統預設使用金鑰驗證 (如下圖),可是我們就是要加入金鑰阿,所以要修改/etc/ssh/sshd_config檔案,將密碼驗證開啟。(GCE 上的 Ubuntu 預設是 PasswordAuthentication no)

sudo vim /etc/ssh/sshd_config將 PasswordAuthentication 改為 yes
# Change to no to disable tunnelled clear text passwords
PasswordAuthentication yes
修改完後,重新啟動 SSH 服務,再試試看
sudo service ssh restart4. 安裝 Java
在兩台電腦中安裝 Java jdk
sudo apt-get install openjdk-7-jdk安裝好後可以查看版本,確認是否有成功安裝
java -versionjava version "1.7.0_91" OpenJDK Runtime Environment (IcedTea 2.6.3) (7u91-2.6.3-0ubuntu0.14.04.1) OpenJDK 64-Bit Server VM (build 24.91-b01, mixed mode)
5. 安裝 Hadoop
這邊我裝的是 2.6.0 版本,因為當時看網路的教學比較多人用這版本,想說有問題比較好解決
先在 master 執行以下指令上安裝,之後再用 scp 複製到 slave1
sudo wget http://ftp.twaren.net/Unix/Web/apache/hadoop/common/hadoop-2.6.0/hadoop-2.6.0.tar.gz
sudo tar -zxvf hadoop-2.6.0.tar.gz
sudo mv hadoop-2.6.0 /opt/hadoop
sudo chown -R hadoopuser:hadoop /opt/hadoop
cd ~
mkdir hdfs
mkdir /home/hadoopuser/hdfs/name
mkdir /home/hadoopuser/hdfs/data
mkdir /home/hadoopuser/tmp說明
- 下載 Hadoop 2.6.0 版
- 將 Hadoop 解壓縮,移動到要存放的位置 /opt/hadoop
- 設定資料夾的擁有者為 hadoopuser
- 建立一個 HDFS 空間 (可以自行決定位置),我放在 home/hdfs
6. 設定 Hadoop
在 .bashrc 檔案中加入環境變數,設定 Hadoop 以及 Java 的位置
sudo vim ~/.bashrc# Set HADOOP_HOME
export HADOOP_HOME=/opt/hadoop
# Set JAVA_HOME
export JAVA_HOME=/usr/lib/jvm/java-7-openjdk-amd64
# Add Hadoop bin and sbin directory to PATH
export PATH=$PATH:$HADOOP_HOME/bin;$HADOOP_HOME/sbin
export HADOOP_CLASSPATH=$JAVA_HOME/lib/tools.jarHadoop 的兩個檔案 (hadoop-env.sh,yarn-env.sh) 也要加入 Java 環境變數
sudo vim /opt/hadoop/etc/hadoop/hadoop-env.sh
sudo vim /opt/hadoop/etc/hadoop/yarn-env.shexport JAVA_HOME=/usr/lib/jvm/java-7-openjdk-amd64修改 core-site.xml
sudo vim /opt/hadoop/etc/hadoop/core-site.xml<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoopuser/tmp</value>
</property>
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>master</value>
</property>
<property>
<name>hadoop.proxyuser.root.group</name>
<value>*</value>
</property>修改 hdfs-site.xml
sudo vim /opt/hadoop/etc/hadoop/hdfs-site.xml<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:9001</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/hadoopuser/hdfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/hadoopuser/hdfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.webhdfs.enable</name>
<value>true</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>新增並修改 mapred-site.xml
Hadoop 目錄下沒有 mapred-site.xml 這個檔案,要複製 mapred-site.xml.template 並把他更名為 mapred-site.xml
sudo cp /opt/hadoop/etc/hadoop/mapred-site.xml.template /opt/hadoop/etc/hadoop/mapred-site.xml
$ sudo vim /opt/hadoop/etc/hadoop/mapred-site.xml<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>修改 yarn-site.xm
sudo vim /opt/hadoop/etc/hadoop/yarn-site.xml<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:8088</value>
</property>6. 將設定檔複製至 slave
因為 /opt/hadoop 資料夾擁有者為 hadoopuser,我們如果直接用 scp 複製到 slave1 的 /opt 下,會 permission denied
因此先在 slave1 下建立 /opt/hadoop 資料夾,擁有者設為 hadoopuser
cd /opt
sudo mkdir hadoop
sudo chown hadoopuser:hadoop hadoop/將檔案從 master 複製到 slave1
scp -r /opt/hadoop slave1:/opt7. 在 master 中加入 slave 的 hostname
編輯 slaves 檔案
sudo vim /opt/hadoop/etc/hadoop/slaveslocalhost slave18. 格式化 Namenode
hdfs namenode -format9. 執行 hadoop
/opt/hadoop/sbin/start-all.sh如果沒有出意外,會很順利地跑完,如下圖
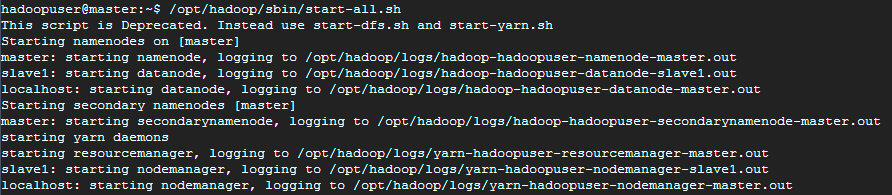
10. 確認是否成功運作
jps用 jps 可以列出所有執行中的 java process,我們拿來檢核 Hadoop 服務有沒有成功跑起來 會在 master 看到
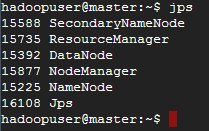
在 slave 看到
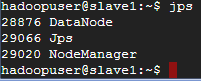
如果有缺少 DataNode,可以試試刪除 hdfs 與 tmp 資料夾,並重新格式化 NameNode