在網路世界裡,只有流量才是真的。
對於部落客來說,我們都希望辛苦撰寫的文章能被大家看到,費盡心思彙整的知識能發揮它的價值,所以除了依靠搜尋引擎的主動曝光外,還會搭配社群媒體、通訊軟體、內容平台等多種方式進行操作,希望創造更多流量,讓自己的部落格發光發熱。
從聳動標題到優質內容
可是,就是有些人不守規矩,想在短時間內衝高流量,依靠不道德的手段不勞而獲,網路上便出現很多標題殺人不償命的內容農場,它藉由人們的好奇心,瘋狂地在社群媒體間流竄
漸漸的,人們對於聳動標題越來越沒有感覺,當某些關鍵字 (比如我震驚了?) 出現的時候,我們很自然地就會想要略過,再加上社群平台開始調整演算法,抵制這種誘騙點擊的連結,也使得農場不得不進行轉型
有些平台開始談合法授權,或把文章進行翻譯加工,但有些平台則是將目標轉移到更直接的流量來源:針對搜尋引擎優化 (SEO) 下手。於是農場不再用聳動的標題,開始提供優質內容,彙整更多知識性文章,為的都是爭取你的停留時間,因為當你停留的越久,搜尋引擎就覺得這篇文章越有價值,而農場在網路上的地位,也就越來越高,網頁排名也會持續提升
對於內容授權合作的方式,我深表贊同,畢竟合作雙方都是為了夢想、為了利益而努力,然而偷竊文章的做法實在讓人無法接受,透過霸道的方式,掠奪他人的數位資產,整篇複製貼上就算了,還不附上個原文出處或是引用連結,難道我們這些創作者苦心經營的智慧結晶,就只能任人宰割嗎?
前陣子我也看見部落客社團有人發問,想尋求大家關於文章被盜用的處理方法,說真的,這沒什麼良好的解決方案,透過寄信要求對方將文章下架,或者向內容平台進行申訴,通常都不太會有回應 …
但,真的沒有比較好的做法嗎?
既然無法防止農場盜文,那就增加他的偷竊難度
就好像以前網頁鎖右鍵一樣,不論什麼招數都只是防君子不防小人,有心人士總是能找到方法拿到他想要的資訊。面對文章竊盜,我們除了加強自己的品牌印象、創造原創者的價值之外,其實還可以透過一些小技巧,增加文章的偷竊難度、或者是混淆對方的視聽
讓我們先想一個問題,假如你今天是內容農場主,想要大量抓取網路上的文章,你會怎麼做?
你會每篇點開,然後一篇篇的按下複製貼上嗎?當然不會,這樣太耗費時間了,聰明人當然是透過爬蟲程式,海量不間斷的撈取文章,然後把文章進行適當處理、正規化之後,再發佈到農場之中。
我們要對付的是那些全年無休的爬蟲程式,那種鎖右鍵或在剪貼簿中夾帶版權訊息的老招已經沒用了。有些人只是想要複製幾句話,結果卻發現不能複製或是多夾帶了一些垃圾訊息,那種使用者體驗就很糟,我們不必為了抵制農場,而讓該珍惜的用戶感到不舒服
那有沒有辦法讓爬蟲看到的東西與人們看到的東西不一樣?
透過 UserAgent 這個欄位,我們可以分別真實用戶以及爬蟲程式,例如 Google 機器人無時無刻都在抓取全世界的網頁,我們不能封鎖他呀,如果 Google 收錄不到文章,你在網路上也別想曝光了
但畢竟 UserAgent 也只是個字串,爬蟲程式可以透過一些技巧進行偽裝,很難透過簡單的判斷做防範 …
既然這招沒效,那我就來應用釣魚網站的老招,或者說賣弄些魔術 (?),透過視覺技巧來騙大家拉 XD
透過 CSS 與 JavaScript 將版權資訊隱藏在文章裡
這個想法很簡單,就是預先在文章中埋入版權資訊,接著結合 CSS 以及 JavaScript 讓那段文字消失,透過這種手法,我們應該可以成功欺騙普通等級的爬蟲程式,畢竟他們是大量抓取,並不會在意小細節
可是如果農場方將爬取的文章進行正規化或是加入其他偵測手法,那這招還是會失效。不過我還是姑且一試,觀察個結果
下圖是我禁用 JavaScript 後,在自己網站上看到的版權資訊
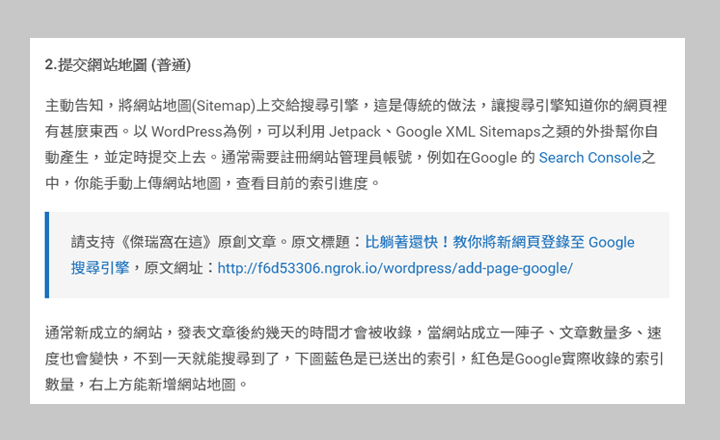
施工的方式很簡單,請分別將下方程式碼加入網站之中
1. HTML (JavaScript)
這段 JavaScript 有很多地方可以安插,像我是加在 post-content.php 裡面。
document.querySelectorAll("pre").forEach(function(e) {
e.innerHTML.startsWith("請支持《")&&e.classList.add("copyright")
});2. style.css
.copyright{
display: none;
}3. functions.php
透過這種方式,我們會在文章第五段的地方塞入版權資訊 (其實跟塞廣告的原理是一樣的 XDD)
<?php
add_filter('the_content', 'add_copyright');
function add_copyright($content)
{
if (!is_single()) return $content;
$paragraphAfter = 5;
$content = explode("</p>", $content);
$post_title = wp_kses_post(get_the_title());
$post_url = esc_url(get_the_permalink());
$copyright = "<pre>請支持《傑瑞窩在這》原創文章。原文標題:<a href='{$post_url}'>{$post_title}</a>,原文網址:<a href='{$post_url}'>{$post_url}</a></pre>";
$new_content = '';
for ($i = 0; $i < count($content); $i++) {
if ($i == $paragraphAfter) {
$new_content.= $copyright;
}
$new_content.= $content[$i] . "</p>";
}
return $new_content;
}不過你可能會問,為什麼要那麼費工,同時使用 CSS 以及 JavaScript?
想要達到隱藏的效果,只用其中一個就行拉。我這邊只是想做的更全面一點,確保你必須載入所有資源才會隱藏版權資訊,而且如果只有爬取 HTML 的話,從 HTML Tag 之中是看不出異樣的,而根據實際測試結果,我發現還有很多研究空間,也歡迎有志之士一起討論。
終於,農場把我的版權資訊收錄進去了
默默的導入網站之後,沒過多久果然被農場給收錄拉,去他的掃文資訊,以下有圖為證
盜文位置:https://hk.saowen.com/a/418c279d5aba3cb0a00082b1e291fd281930fc32ba2b6751cad60f8a9080e1e9
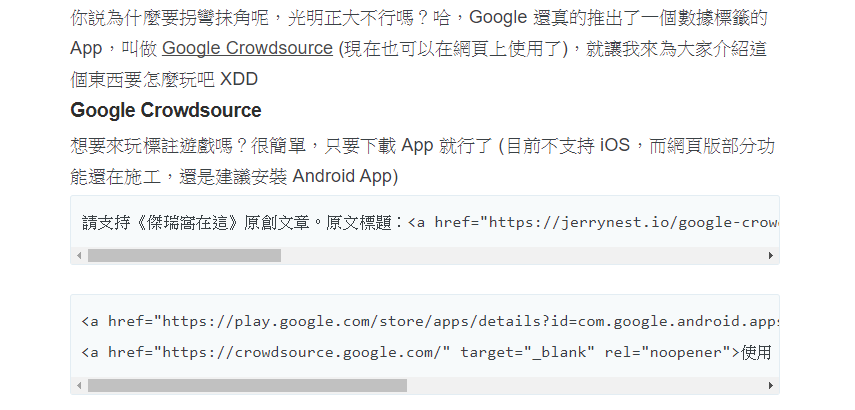
比較遺憾的部分是他針對 pre 標籤做了轉換,我原先預期他會顯示出網址連結的,看來思維要換一下,不應該以自己網站的 CSS 樣式為基準。但至少有顯示出「請支持《傑瑞窩在這》原創文章」這句話,算是心滿意足了
另外一個大陸站案例「酷辣蟲」,則是成功收錄版權訊息 XDDD
盜文位置:https://www.colabug.com/2516272.html
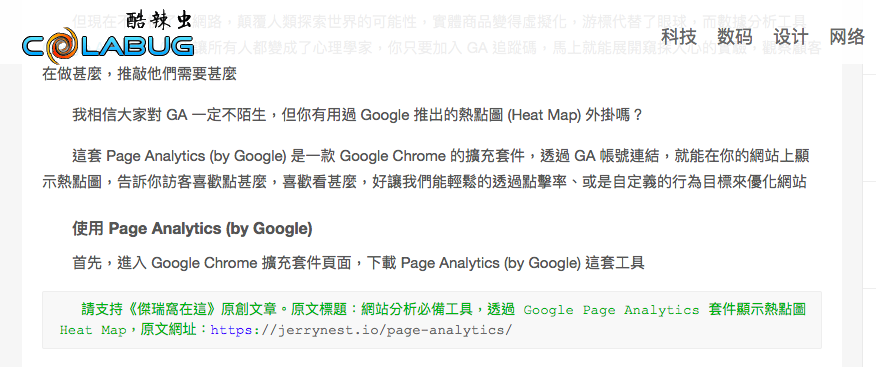
簡單的爬蟲實驗
最後也提供當時的測試實驗給大家參考,以下是實際的爬蟲程式,看看會抓到甚麼東西
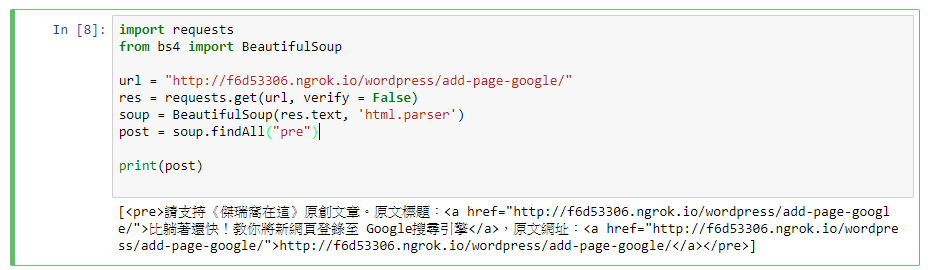
方法1:透過 Python Requests 來驗證效果
import requests
from bs4 import BeautifulSoup
url = "http://f6d53306.ngrok.io/wordpress/add-page-google/"
res = requests.get(url, verify = False)
soup = BeautifulSoup(res.text, 'html.parser')
post = soup.findAll("pre")
print(post)單純只有抓取 HTML,版權資訊肯定不會消失的
方法 2:透過 Google Chrome 無介面瀏覽器來驗證效果
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.setJavaScriptEnabled(true);
await page.goto('http://f6d53306.ngrok.io/wordpress/add-page-google/', {"waitUntil" : "networkidle0"});
const pres = await page.$eval('pre', e => e.outerHTML);
console.log(pres);
await browser.close();
})();使用瀏覽器開啟網頁仍然會有版權訊息,除非有針對 CSS 屬性做過濾

實在是太痛恨這種文章小偷了!這次落落長的介紹就到這裡囉,我正在研究有沒有更好的方式,如果各位有甚麼想法也歡迎跟我討論,感謝大家的收看
延伸閱讀
後記
儘管我們無法阻擋別人盜取內容,但還是有辦法製造一些陷阱,留下證據來保護自己。像是最近看到歌詞網站 Genius 控告 Google 盜取內容的新聞,才發現他們真的是聰明呀,利用不同的撇號來創造出獨一無二的「浮水印」,把版權資訊隱藏在文章之中。畢竟,不懂這套規則的人,怎麼可能剛好會這樣使用這些撇號呢?
雖然 Google 聲稱這些資料是由合作夥伴 LyricFind 提供,但還是證實「複製資料」輕而易舉,常常在發生,可不要以為你複製的是到處都有的歌詞,其實裡面還是有些微不同的 XDD


十分有用的分享!對於廣泛的話題,我已經放棄文字,直接上YouTube。文字我現在還用一個方法就是利用會員登入才可見的方法,對文章精華進行隱藏。有很好的作用是可以對會員進行remarketing, 當然這是對於我這種lead generation型的blog最為適用。
Hello 謝謝你的分享,內容主題很明確的話,確實可以走向會員制或者建立自己的社群。但我算是走比較隨興的路線,開心就寫,後來會覺得寫作的當下是快樂的就好,也沒有那麼 care 文章被偷了
您好,最近在找防止盜文的方式,搜尋到您的這篇文章。
我的部落格也是使用Wordpress,所以想試試您的這個方式來修改看看。
不過看完您的文章,我有一點小小的問題,
就是文章中要修改Html的部份,指的是部落格Theme的那一個檔案?
Hello 狐貍,
這段 JavaScript 有很多地方可以安插,像我是加在 post-content.php 裡面唷,如此一來每篇文章都會生效
寫謝您的回應,我試試看。
最近很容易搜到掃文資訊, 他的seo好像做得不錯.
他好像掃蠻多技術文章的,常常會不小心點到,現在反而很少看到「壹讀」了XD
您好,不過我發現
e.innerHTML.startsWith(“請支持《”);
這一行似乎沒有效果椰,我也嘗試改成 includes的語法,不過不管怎麼樣所有有pre標籤的都會被加上copyright class,結果文章當中的pre標籤通通都被隱藏起來。
Hi ヤンヤン,
不好意思這邊是我寫錯了,應該是用 && 連接才對
代表符合條件才加上 copyright class
已經更新囉
哇!就是這個!我一直想要找的方式wwww
Yaaaa 有幫助到大家我就很開心