延續之前的文章,這篇主要是記錄我怎麼透過 Google Cloud 上面的服務來組合出一條資料管線,把 COVID-19 移動趨勢報告與確診數做關聯,打造一個可以每天自動更新的武漢肺炎 COVID-19 儀表板。
還沒收看過前一篇文章的朋友們,可以先點擊下方連結看一下 Google 與 Apple 的移動趨勢報告分析,會對這份資料與儀表板的建置有更深入的了解。
傳送門:分析 Google 與 Apple 的移動趨勢報告:COVID-19 Community Mobility Reports
使用省錢的方法建置
想要定時更新資料,開一台虛擬機,寫一個排程任務(Cron job)也是做得到,為什麼要大費周章搞一條資料管線呢?
省錢!省錢!省錢!
使用雲端服務必須要精打細算,一台虛擬機器開在那邊,要燒很多錢呀,我們平常老百姓承受不起。
對於一個小專案來說,功能簡單,沒有 migrate 的限制,這種定時做某件事情的工作,不用虛擬機器,直接使用 Cloud Function 就可以了。
當然,除了省錢之外,這次也是要練習使用這些雲端功能,想說之後需要用到的時候比才知道怎麼接 😎
建立資料管線
整條資料管線滿簡單的,只要在 GCP Console 上面操作就可以完成。
我原本還想說要來寫個腳本,做到 Infrastructure as Code,但想說只有一個 Python 程式在執行,直接上去手動更新檔案就好了,懶惰 ing 😂
整條水管長這樣。透過 Cloud Scheduler 發起事件,觸發 Cloud Function 執行資料下載與合併的工作,之後把結果丟到 Cloud Storage,最後在 Data Studio 顯示結果。
為了畫出這張圖,還特別 Google 一下,找到這個用於製作 GCP 架構圖的官方圖示集:架構圖解決方案圖示,可惜裡面沒有 Cloud Scheduler,要自己匯入。
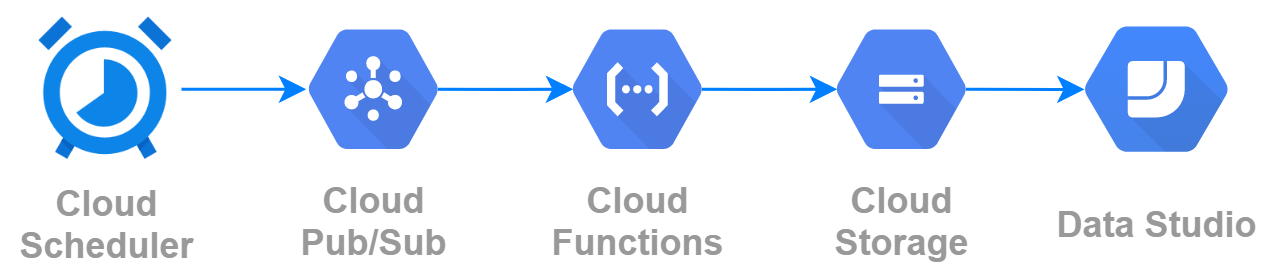
水管包含這幾個項目:
- Cloud Scheduler 每天早上會發起事件,發出一個事件給 Cloud Pub/Sub
- Cloud Pub/Sub 會觸發訂閱中的 Cloud Function
- Cloud Function 會執行一隻 Python 程式,處理資料下載與合併的工作
- Cloud Function 會將合併好的資料儲存到 Cloud Storage
- Data Studio 可以看到最新的資料
這篇文章都是參考這篇教學一步步完成的,如果你也想要打造資料自己的資料管線,歡迎參考:
教學文件:Using Pub/Sub to trigger a Cloud Function
1. Cloud Scheduler
Cloud Scheduler 是一個簡單的排程管理器,透過 crontab 的格式設定甚麼時候要觸發事件。稍微要注意自己建立的時區是甚麼,以免觸發時間搞錯。

2. Cloud Pub/Sub
Cloud Pub/Sub 是用來處理發布與訂閱這種非同步事件的服務。以日常生活為例子,可以想像你訂閱追蹤某個 YouTube 頻道,等到那個頻道有新影片上架的時候,你就會收到頻道主動推播的訊息。
簡單的說,這裡就是要讓 Cloud Function 去訂閱 Cloud Scheduler。
3. Cloud Function
Cloud Function 就是實際工作的主角,我們把寫好的 Python 程式放上去,讓他工作。
只要先把前面的步驟串起來,就可以去 Cloud Scheduler 那邊點「立即執行」來觸發 Cloud Function 測試自己的程式是不是正常運作。當然,也可以直接用 Cloud Function 本身自帶的測試功能,相關的除錯訊息也都看的到。
前面提到,我們要把人流資料與確診數做關聯,因此這邊會分別向兩個資料來源下載 CSV 檔案,然後根據國家來做合併。兩個資料來源分別是:
資料下載與合併 程式碼
因為程式碼也沒有很多,就直接在這邊分享給大家。這邊有幾個重點稍微說明一下:
- 在資料合併時我做了簡化,只根據國家做對應,所以每個國家內的所有區域資料將會全部合併,以至於目前的篩選器最多只能塞選國家,沒辦法篩選區域。
- 兩份資料的日期格式與國家名稱有些許不同,我做了一個簡單對應。
requirements.txt
pandas==1.0.3
numpy==1.18.4
requests==2.23.0
google-cloud-storage==1.28.1main.py
from google.cloud import storage
import pandas as pd
import numpy as np
import datetime
import requests
import csv
import json
import os
mobility_report_url = 'https://www.gstatic.com/covid19/mobility/Global_Mobility_Report.csv'
confirmed_global_url = 'https://data.humdata.org/hxlproxy/api/data-preview.csv?url=https%3A%2F%2Fraw.githubusercontent.com%2FCSSEGISandData%2FCOVID-19%2Fmaster%2Fcsse_covid_19_data%2Fcsse_covid_19_time_series%2Ftime_series_covid19_confirmed_global.csv&filename=time_series_covid19_confirmed_global.csv'
deaths_global_url = 'https://data.humdata.org/hxlproxy/api/data-preview.csv?url=https%3A%2F%2Fraw.githubusercontent.com%2FCSSEGISandData%2FCOVID-19%2Fmaster%2Fcsse_covid_19_data%2Fcsse_covid_19_time_series%2Ftime_series_covid19_deaths_global.csv&filename=time_series_covid19_deaths_global.csv'
recovered_global_url = 'https://data.humdata.org/hxlproxy/api/data-preview.csv?url=https%3A%2F%2Fraw.githubusercontent.com%2FCSSEGISandData%2FCOVID-19%2Fmaster%2Fcsse_covid_19_data%2Fcsse_covid_19_time_series%2Ftime_series_covid19_recovered_global.csv&filename=time_series_covid19_recovered_global.csv'
output_path = "/tmp/output/output.csv"
def merge_global_data_row(data_input):
aggregation_functions = {'Country/Region': 'first'}
for column in data_input.columns[4:]:
aggregation_functions[column] = 'sum'
data_output = data_input.groupby(data_input['Country/Region']).aggregate(aggregation_functions)
return data_output
def merge_mobility_report_row(data_input):
aggregation_functions = {'country_region': 'first', 'date': 'first'}
for column in data_input.columns[5:]:
aggregation_functions[column] = 'sum'
data_output = data_input.groupby(['country_region', 'date']).aggregate(aggregation_functions)
return data_output
def load_csv_from_url(url):
df = pd.read_csv(url)
return df
def download_csv(url, filename):
df = pd.read_csv(url)
df.to_csv(filename, index=False)
def convert_date_format(date_list):
# convert the date format from %m/%d/%y to %Y/%m/%d
output = []
for item in date_list:
datetime_obj = datetime.datetime.strptime(item, '%m/%d/%y')
output.append(datetime_obj.strftime('%Y/%m/%d'))
return output
def mapping_contry_name(name):
if name == 'Taiwan':
return 'Taiwan*'
elif name == 'United States':
return 'US'
elif name == 'South Korea':
return 'Korea, South'
else:
return name
def process(event, context):
# load files
data_mobility_report = load_csv_from_url(mobility_report_url)
data_confirmed = merge_global_data_row(load_csv_from_url(confirmed_global_url))
data_deaths = merge_global_data_row(load_csv_from_url(deaths_global_url))
data_recovered = merge_global_data_row(load_csv_from_url(recovered_global_url))
# merge data
data_mobility_report_group = merge_mobility_report_row(data_mobility_report)
data_mobility_report_group = data_mobility_report_group.reset_index(drop=True)
case_data_contry_list = data_confirmed['Country/Region'].tolist()
data_output = None
for contry_name, row in data_mobility_report_group.groupby(['country_region']):
mname = mapping_contry_name(contry_name)
total = data_confirmed.iloc[:,25:].shape[1]
diff = total - row.shape[0]
table = np.zeros((diff, row.shape[1]))
df = pd.DataFrame(table, dtype=np.int, columns=row.columns)
df['country_region'] = contry_name
df['date'] = convert_date_format(list(data_confirmed.columns[-diff:]))
df2 = pd.concat([row, df], axis=0)
if mname in case_data_contry_list:
data_confirmed_pick = data_confirmed.loc[data_confirmed['Country/Region'] == mname].iloc[:,25:].T[mname].values
data_deaths_pick = data_deaths.loc[data_confirmed['Country/Region'] == mname].iloc[:,25:].T[mname].values
data_recovered_pick = data_recovered.loc[data_confirmed['Country/Region'] == mname].iloc[:,25:].T[mname].values
print(contry_name, row.shape, data_confirmed_pick.shape)
else:
data_confirmed_pick = np.zeros(total)
data_deaths_pick = np.zeros(total)
data_recovered_pick = np.zeros(total)
df2['confirm_count'] = data_confirmed_pick
df2['deaths_count'] = data_deaths_pick
df2['recovered_count'] = data_recovered_pick
if data_output is None:
data_output = df2
else:
data_output = data_output.append(df2)
os.makedirs(os.path.dirname(output_path), exist_ok=True)
data_output.to_csv(output_path, index = False, header=True)
client = storage.Client()
bucket = client.get_bucket('bucket-name')
blob = bucket.blob('output.csv')
blob.upload_from_filename(filename=output_path)4. Cloud Storage
這個就是儲存檔案的空間,開設一個自己的 bucket。
題外話,最近聽到 AWS 的課程在教 S3,中文的教學是直接把 bucket 翻譯成「桶」哈哈,從這個私有桶到公有桶甚麼的,聽起來怪饒口的。
5. Google Data Studio
最後一步,就是設定 Data Studio 去吃 Cloud Storage 來源的資料,設定完成拖拉幾下就可以建置好報表。關於 Data Studio 的介紹,可以參考我之前的文章:
使用 Google Data Studio 數據分析工具,輕鬆打造 Google Analytics 視覺化報表
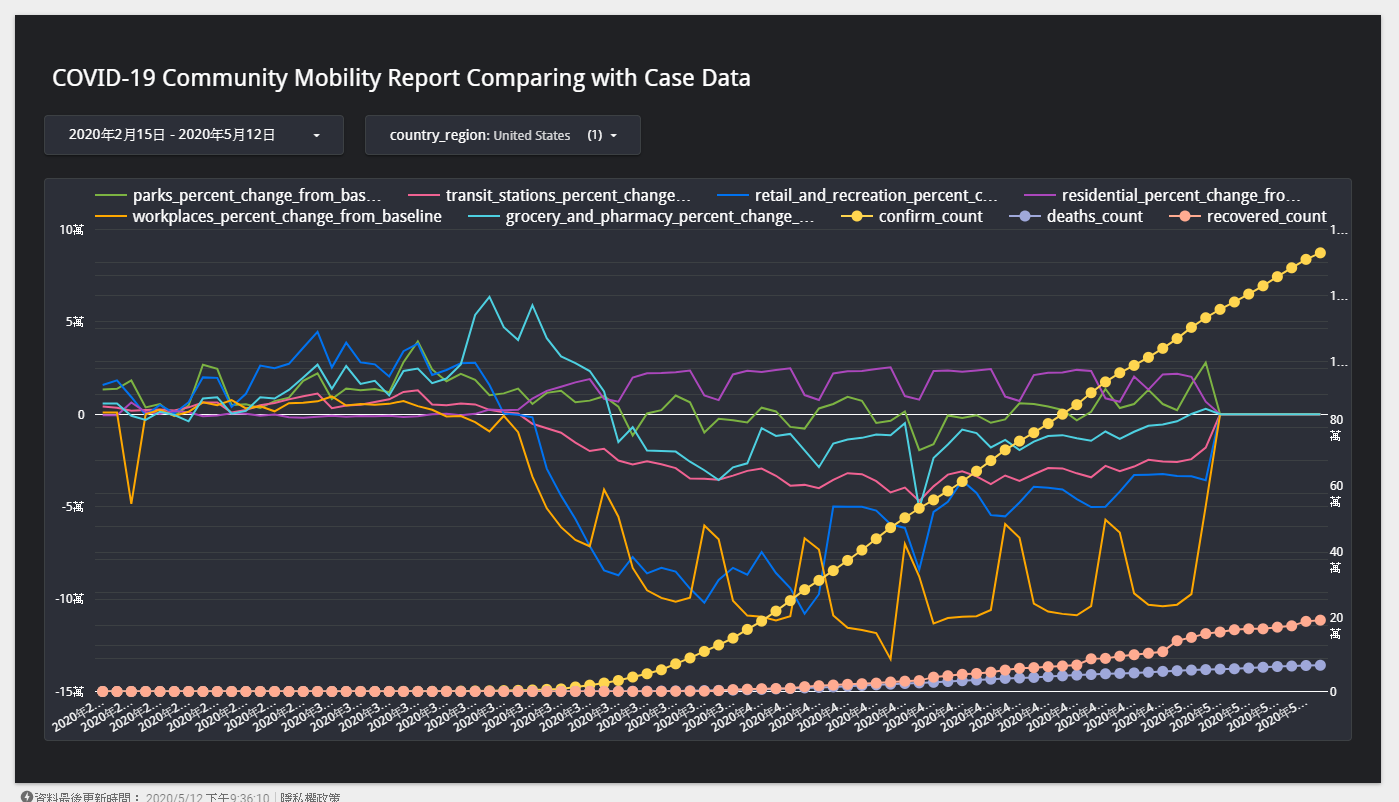
最後的成果就如下圖所示,有興趣的話,可以點擊下方的連結前往觀看。如果資料有誤,歡迎在留言區告訴我,我會盡快修補問題。
傳送門:COVID-19 移動趨勢報表 (已下架)
這樣花費多少呢?
串了那麼多服務,要花到錢嗎?答案是:不用啦!
我們來盤點一下,目前有用到的服務們的免費額度有多少,詳細還是要參考 GCP 官方的文件。
- Cloud Scheduler:每個 Google 帳單帳戶每個月可免費建立 3 項工作。
- Cloud Pub/Sub:系統會根據擷取和傳送訊息作業每月所傳輸的資料量計費,前 10 GB 的用量免費。
- Cloud Function:每月前 200 萬次叫用免費。免費方案也提供 400,000 GB/秒和 200,000 GHz/秒的運算時間,以及每月 5 GB 的網際網路輸出流量。
- Cloud Storage:每月 5 GB 的免費用量。因為每天只做一次事情,A 與 B 級作業的額度都不會超過。
- Google Data Studio:不用錢 YA
總結
很開心完成了一個簡單的 Side Project,也對於 GCP 上面的這幾個服務有更深入的了解。
不過跟 AWS 相比之下,Google Cloud 的功能顯得實在陽春許多,還要加把勁才能追上老大哥 TAT
真的要說的話,我還是比較喜歡 Google Data Studio,跟打對台的 Amazon QuickSight 相比,Google 的 UI 呈現還是深得我心,做出來的成品看的愉悅啊 XDD


Jerry你好:
請問function有這個error,要怎麼辦?
TypeError: merge_global_data_row() takes 1 positional argument but 2 were given
Hi 家維,
這個錯誤是參數數量不對,可以分享您完整的程式碼嗎?
目前我簡單測試看起來沒有問題
Regards,
Jerry
你的Cloud Function程式不能用
純粹炫耀文?當個版膩?????
Hello 小妍,
謝謝你的回應,這篇文章當作是我的學習兼紀錄,供大家參考。
如果程式不能動,有可能是資料來源的欄位有更新,導致爬蟲程式執行失敗。
建議你可以先看一下錯誤訊息,我們來看看是哪邊有問題,然後進行調整。
Regards,
Jerry
之前受你跟老師上課指導 我也比較喜歡用Google cloud console來作事
Hello 學長好久不見 🙂
GCP 真的是介面取勝哈哈
我也是習慣用他xdd