之前撈網站資料都用 Python 的 Beautiful Soup,覺得已經很方便了,不過在 SITCON 聽講者介紹 Pandas,發現用它來抓網頁表格更方便快速呀!
Pandas 一樣是 Python 套件,可以擷取 JSON、CSV、Excel 與 HTML 等等格式的資料。資料型態為 DataFrame 格式,可以使用 Index(Row) 或 Column 存取資料,整理資料的時候相當好用。
開發環境
- 這篇文章使用的是較舊的 Python 2.x
- 使用 iPython 來協助開發
- 由於用 Pandas 爬 HTML 還需要額外裝一些東西,在 Windows 安裝遇到點問題,所以使用 Mac 環境測試。
安裝必要套件
在 Mac 環境下,需要先裝 libxml2 與 libxslt
brew install libxml2
brew install libxslt
brew link libxml2 --force
brew link libxslt --force接著裝以下套件即可完工
pip install lxml
pip install html5lib
pip install beautifulsoup4
pip install pandas使用 Pandas 匯入資料
可以匯入 CSV、Excel 與 HTML 等多種格式,使用方式簡單如下:
import pandas as pd
data = pd.read_csv('file.csv')
data = pd.read_excel('file.xls', 'sheet')
data = pd.read_html('url')檔案讀取進來後,就是要畫圖呈現拉!可以參考 Pandas 網站上的 Visualization 章節,使用 Matplotlib API 繪圖。這部份就自行點閱 Pandas官網。
此外,Pandas 也提供方便的功能,直接顯示統計資訊與相關係數。
data.describe()
data.corr()文字編碼問題
讀取中文的時候常常會出現亂碼,原因就是編碼不如預期,比如說 utf-8。通常在 Python 檔案前面加上以下文字就能一勞永逸,但有些時候還是會有問題。
# -- coding: utf-8 --
老師的投影片舉了以下例子,使用 raw_input 的時候,若沒有加上 Unicode 編碼,輸出就會產生亂碼,改進的方式如下
name = raw_input(u" 請輸入你的名字: ")
print " 你好! " + name.decode(s).encode("utf-8")範例程式
實測 Pandas:抓取 StockQ.org 上的股市資料。 網頁上的資料明顯是一個表格,適合用 Pandas 直接抓取。如下圖:
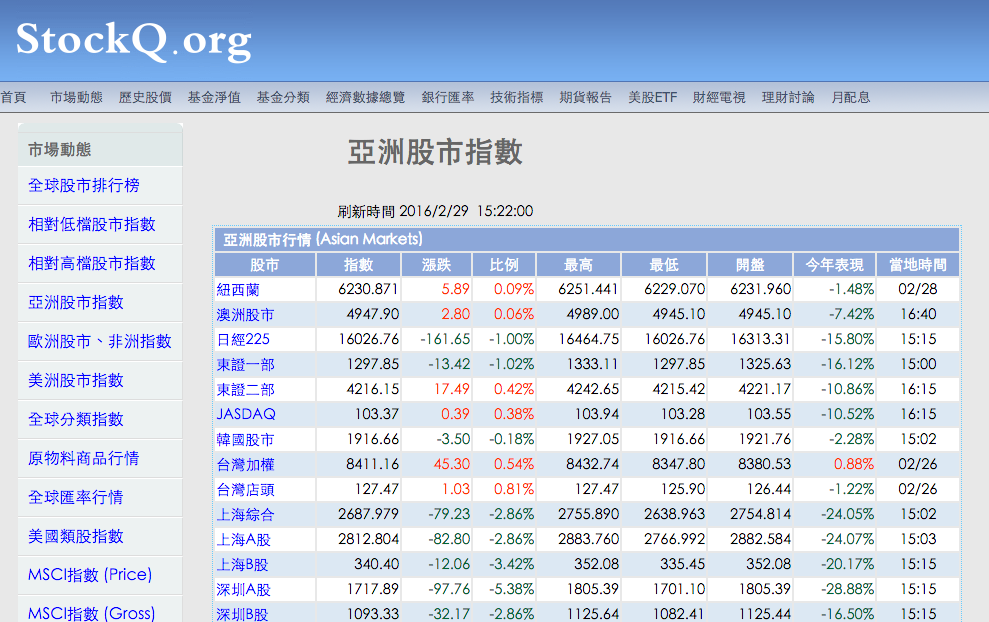
接著我們直接利用 read_html 抓取表格資料
import pandas as pd
url = 'http://www.stockq.org/market/asia.php'
pd.read_html(url)[4]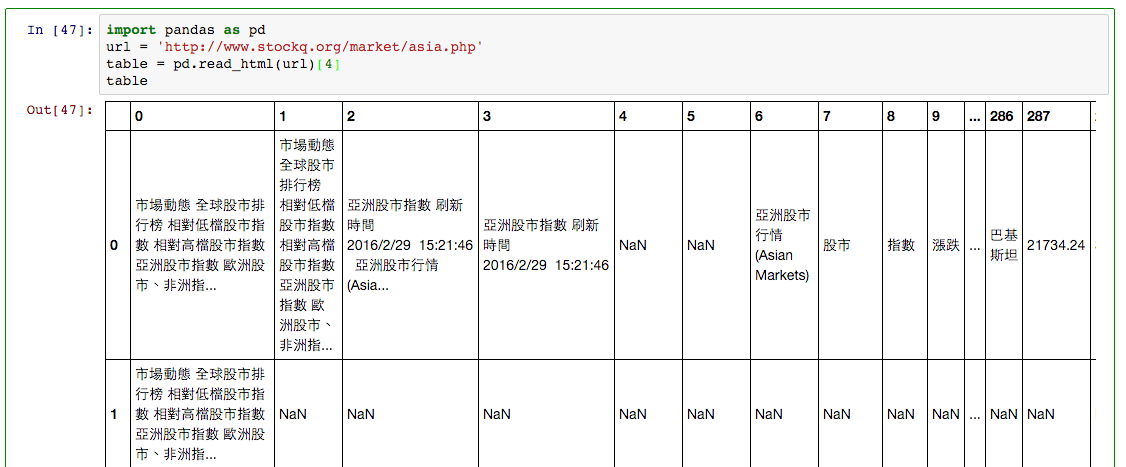
這個網頁上有多個表格,而我們關注的股市資料放在第五個表格中,因此下指令 read_html(url)[4] 拿到第五個表格的資料。
但仔細一看,居然有 287 個 Column?網頁上明明沒有那麼多呀,這裡先不管是不是 HTML 寫的問題,我們用 drop 指令把不要的 Row 與 Column 丟掉,留下想要的表格!
import pandas as pd
url = 'http://www.stockq.org/market/asia.php'
table = pd.read_html(url)[4]
table = table.drop(table.columns[[0,1,2,3,4]],axis=0)
table = table.drop(table.columns[9:296],axis=1)
table抓取資料的說明就到這,接下來就是處理資料囉。

BeautifulSoup4(bs4) 也需要喔~
python -m pip install bs4
謝謝你喲~